В операционной системе версии 4 к планировщику CPU была добавлена поддержка нитей. В целом алгоритм планирования и схема приоритетов остались прежними, однако для поддержки нитей потребовалось изменить множество мелких деталей. И хотя для старых приложений, работающих в однопроцессорных системах, эти изменения будут практически незаметны, у вас должно быть представление о внесенных изменениях и новых возможностях для настройки системы.
Нитью называется процесс, использующий небольшой объем ресурсов. Это управляемый объект, для создания которого требуется меньше ресурсов, чем для обычного процесса. В операционной системе AIX версии 4 планировщик работает с нитями.
Процессы продолжают применяться наряду с нитями. Операционная система точно так же, как и раньше, создает процессы приложений, перенесенных из более младших выпусков, и управляет ими. Такие процессы создаются в виде единичных нитей с приоритетом родительского процесса, которые конкурируют за ресурсы CPU с нитями других процессов. Процесс владеет ресурсами, которые используются при выполнении; у нити есть только ее текущее состояние.
Все дополнительные нити новых или обновленных приложений создаются в контексте процесса. Они работают с общим сегментом памяти процесса и другими ресурсами.
С пользовательской нитью процесса связана область действия. Нить с глобальной областью действия конкурирует за CPU со всеми остальными нитями системы. Нить, создаваемая одновременно с процессом, всегда имеет глобальную область действия. Нить с локальной областью действия конкурирует только с нитями этого же процесса за долю времени CPU, выделенную процессу.
Алгоритм выбора следующей нити для выполнения называется стратегией планирования.
Процесс представляет собой набор действий, выполняемых системой. Он может быть запущен командой, программой оболочки или другим процессом.
С процессом связаны следующие свойства:
Эти свойства описаны в файле /usr/include/sys/proc.h.
С нитью связаны следующие свойства:
Эти свойства определены в файле /usr/include/sys/thread.h.
Каждый процесс состоит из одной или нескольких нитей. Нить представляет собой упорядоченный поток управления. Несколько нитей, или потоков управления, позволяют приложению параллельно выполнять несколько операций, например, считывать данные с терминала и записывать данные в файл.
Кроме того, приложение, разбитое на несколько нитей, может одновременно выполнять запросы нескольких пользователей. Нити позволяют использовать эти возможности, не требуя такого объема ресурсов, как процессы, создаваемые с помощью системных вызовов fork().
В операционной системе AIX 4.3.1 появилась функция f_fork(), предназначенная для быстрого порождения процесса. Эта функция особенно полезна в тех приложениях с несколькими нитями, в которых сразу за вызовом fork() вызывается exec(). Функция fork() работает относительно медленно, так как она вызывает несколько обработчиков для получения блокировок на все библиотеки, и лишь затем порождает дочерний процесс и позволяет ему запустить все необходимые обработчики для инициализации блокировок. Функция f_fork() не вызывает эти обработчики, сразу переходя к системному вызову kfork(). Примером приложений, в которых может использоваться функция f_fork(), являются Web-серверы.
В операционной системе предусмотрены специальные средства управления приоритетом процессов. В операционной системе AIX версии 4 приоритет процесса наследуется нитью. При вызове функции fork() создается процесс и одна его нить. Нить получает такой приоритет, который раньше был бы присвоен процессу.
Значение приоритета нити (который иногда называется приоритетом планирования) хранится в ядре. Приоритет - это натуральное число, обратно пропорциональное важности нити. Таким образом, чем меньше приоритет, тем важнее нить. Планировщик выбирает для запуска нить с наименьшим значением приоритета.
Приоритет нити может быть фиксированным или переменным. Фиксированный приоритет нити - это константа, тогда как переменный приоритет зависит от минимального приоритета пользовательских нитей (40), составляющей приоритета, задаваемой командой nice или renice (по умолчанию равно 20) и штрафа за использование процессора.
С помощью функции setpri() для нити можно установить фиксированный приоритет, меньший 40. Приоритет таких нитей не пересчитывается планировщиком. Нити с фиксированным приоритетом меньше 40 будут запущены и выполнены раньше всех пользовательских нитей. Например, нить с фиксированным приоритетом 10 будет запущена раньше, чем нить с фиксированным приоритетом 15.
С помощью команды nice пользователь может увеличить переменный приоритет нити. Администратор системы может указать в команде nice отрицательный аргумент, чтобы уменьшить приоритет нити.
Ниже показано несколько способов изменения приоритета.
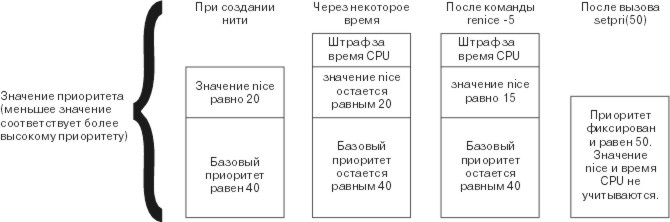
Рис. 2-1. Способ определения приоритета. На приведенном рисунке показано, каким образом приоритет планирования нити может измениться в процессе выполнения или после применения команды nice. Чем меньше значение приоритета, тем выше приоритет нити. Вначале значение nice составляет 20, а базовый приоритет - 40. В течение некоторого времени после запуска значение nice остается равным 20, а базовый приоритет - 40. После вызова команды renice --5 значение nice стало равным 15, а базовый приоритет остался равен 40. После вызова функции setpri() с аргументом 50 был установлен фиксированный приоритет 50, не зависящий от значения nice и штрафа за использование процессора.
Значение nice устанавливается при создании нити и изменяется только явным образом с помощью команды renice, либо системного вызова setpri(), setpriority(), thread_setsched() или nice().
Штраф за использование CPU - это целочисленное значение, которое пропорционально объему ресурсов CPU, затраченных на выполнение нити за последнее время. Показатель использования CPU увеличивается примерно на 1 в конце каждого интервала времени длиной 10 мсек, если в этот момент управление принадлежит данной нити. Максимальное значение равно 120. Штраф, назначаемый с каждым тактом процессора, возрастает вместе со значением nice. Раз в секунду показатели использования CPU пересчитываются для всех нитей.
В результате:
Приоритет, значение nice и показатель использования CPU процесса можно просмотреть с помощью команды ps.
Дополнительная информация о применении команд nice и renice приведена в разделе Конкуренция за использование процессора.
Более подробная информация о вычислении штрафа за использование CPU и увеличении текущего значения использования CPU приведена в разделе Настройка вычисления значения приоритета нити.
В операционной системе AIX версии 4 поддерживается пять типов стратегий планирования нитей:
Стратегия планирования задается с помощью системного вызова thread_setsched(). Он устанавливает стратегию для той нити, из которой отправлен вызов. Для того чтобы изменить стратегию планирования нити на SCHED_RR можно вызвать функцию setpri(), указав ИД процесса. Процесс, из которого был отправлен вызов setpri(), не обязательно должен совпадать с процессом, заданным в качестве параметра функции setpri().
Системный вызов setpri() может отправляться только процессами с правами доступа root. Кроме того, стратегию планирования могут изменять только нити с правами доступа root. В качестве аргумента они могут указать один из вариантов стратегии планирования SCHED_FIFO или SCHED_RR. Если в качестве параметра функции thread_setsched() будет указана стратегия SCHED_OTHER, то этот параметр будет проигнорирован.
В основном нити предназначены для приложений, которые раньше состояли из нескольких асинхронных процессов. Преобразование таких приложений в структуру из нескольких нитей позволит сэкономить ресурсы системы.
Планировщик поддерживает очередь выполнения, в которой находятся все нити, готовые к выполнению. На приведенном ниже рисунке приведена схема очереди выполнения.
Рис. 2-2. Очередь выполнения. На данном рисунке показано, что нити с более низким значением приоритета, помещаются в очередь выполнения перед нитями с более высоким значением приоритета. Число возможных значений приоритета (от 0 до 127) в точности совпадает с числом очередей выполнения (128).
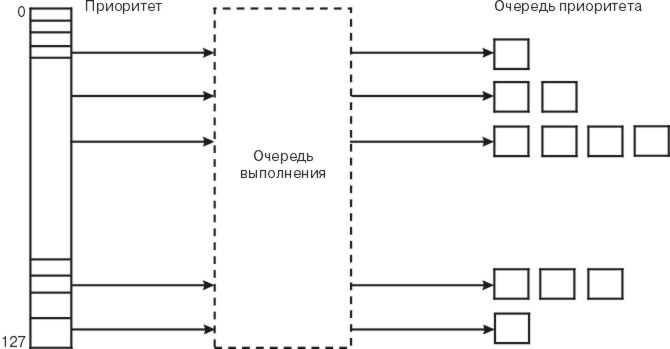
В очереди выполнения расположены все готовые к выполнению нити с одинаковым приоритетом.
Планировщик работает с нитями. В AIX версии 5.1 существует 256 очередей выполнения (в AIX версии 4.3 и ниже - 128). В AIX 5.1 в каждой очереди находятся нити с определенным значением приоритета (от 0 до 255). За счет этого планировщик может быстрее определить, какую нить нужно следующей передать на выполнение. Вместо того чтобы просматривать одну большую очередь выполнения, планировщик создает битовую маску. Если бит маски равен единице, то в соответствующей очереди есть нить, готовая к выполнению.
Приоритет нити изменяется достаточно часто. Постоянное перемещение нитей связано с тем, что планировщик пересчитывает их приоритет. Однако это не относится к нитям с фиксированным приоритетом.
В операционной системе AIX версии 4.3.3 и выше у каждого процессора есть своя очередь выполнения. Информация об очередях выполнения, выдаваемая средствами сбора статистики, будет отражать суммарные значения параметров всех очередей выполнения. Наличие отдельной очереди выполнения для каждого CPU позволяет сократить нагрузку, связанную с управлением блокировками, и более равномерно распределить общую нагрузку по процессорам. Нити будут реже перемещаться с процессора на процессор. Выполнение нити будет продолжено на другом процессоре только в том случае, если в системе есть простаивающий процессор, и на каком-то процессоре произошло событие, в результате которого нить стала готова к выполнению. Если простаивающего процессора нет, то нить будет дожидаться, пока освободиться тот процессор, на котором она выполнялась раньше (например, в результате прерывания).
Если переменная среды RT_GRQ равна ON, то нити будут помещаться в глобальную очередь выполнения. В этом случае планировщик будет выбирать из глобальной очереди выполнения нить с минимальным приоритетом. Такая схема постановки в очередь позволяет ускорить выполнение нитей, для управления которыми применяются прерывания. Нити с фиксированным приоритетом помещаются в глобальную очередь выполнения в том случае, если флаг schedtune -F равен 1.
Для того чтобы узнать среднее число нитей в очереди выполнения, вызовите команду vmstat. Это значение будет указано в первом столбце вывода. Разделив это значение на число CPU, вы получите среднее число нитей, которое может выполняться на одном CPU. Если это значение больше единицы, то указанные нити должны будут ждать своего переключения на CPU (чем больше это значение, тем больше будет время ожидания).
Когда нить помещается в конец очереди выполнения (например, если ей принадлежит управление в конце кванта времени), она занимает место за последней нитью с тем же значением приоритета.
Квантом процессорного времени называется время, по истечении которого выполнение нити с алгоритмом планирования SCHED_RR будет прервано, а управление будет передано другой нити с тем же приоритетом. С помощью опции -t команды schedtune можно увеличить число тактов процессора в кванте времени. Другими словами, квант времени можно увеличивать за счет приращений по 10 миллисекунд (см. раздел Изменение кванта времени планировщика с помощью команды schedtune).
Примечание: Квант времени не является гарантированным квантом времени процессора. Он задает максимальное время, в течение которого нити может принадлежать управление до ее замены другой нитью. Существует множество причин, по которым нить может потерять управление CPU до истечения кванта времени.
Когда пользовательскому процессу нужно захватить ресурсы системы, он изменяет режим выполнения. Это можно сделать с помощью системных вызовов, либо с помощью прерываний (например, страничных ошибок). Существует два режима:
Время работы процессора в пользовательском режиме (при работе с приложениями и общими библиотеками) указывается в выводах команд vmstat, iostat и sar как пользовательское время. Время работы CPU в системном режиме указывается в выводе этих команд как системное время.
В пользовательской области защиты выполняются пользовательские процессы. Такие процессы выполняются в пользовательском режиме. Им предоставлены следующие права доступа:
У программ, выполняемых в пользовательской области защиты, нет прав доступа к области памяти ядра и области памяти данных ядра. Для обращения к этим областям памяти должны применяться системные вызовы. Программа из этой области защиты может изменять только собственную среду выполнения. Она выполняется как обычный процесс в непривилегированном режиме.
В системной области защиты выполняются обработчики прерываний, основные функции ядра и расширения ядра (драйверы устройств, системные вызовы и функции для работы с файловыми системами). Программы из системной области защиты выполняются в системном режиме. Им предоставляются следующие права доступа:
К пользовательским данным, расположенным в адресном пространстве процесса, можно обращаться только через соответствующие службы ядра.
Программы из этой области защиты могут изменять среду выполнения всех программ, так как они обладают следующими свойствами:
С помощью системных вызовов, процессы, выполняющиеся в пользовательском режиме, могут обращаться к функциям ядра. Функции, которые явно или косвенно используют системные вызовы, обычно расположены в библиотеках программ, предоставляющих доступ к функциям операционной системы.
Следует отличать переключение режима от переключения контекста, которое указывается в выводе команд vmstat (столбец cs) и sar (cswch/s). Переключение контекста происходит в том случае, если на процессоре была запущена другая нить.
Планировщик переключает контекст в следующих случаях:
Суммарное время, затраченное процессором на переключение контекста, выполнение системных вызовов, обработку прерываний устройств, ввод-вывод NFS и выполнение других операций в ядре называется системным временем.