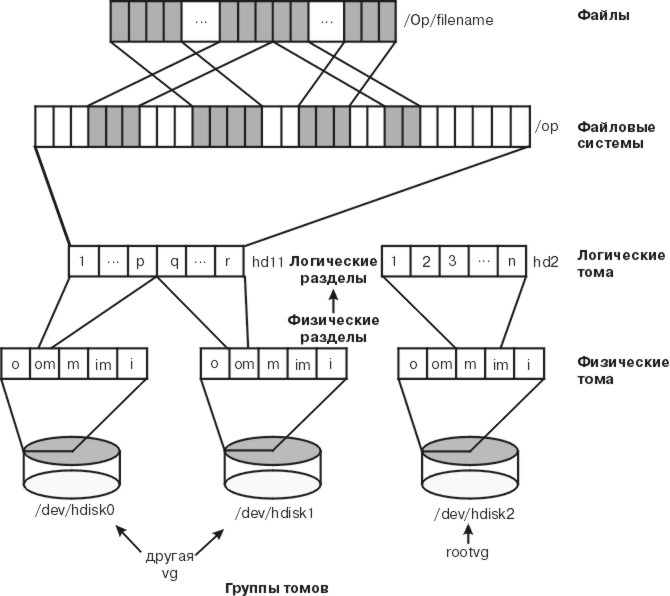
На приведенном ниже рисунке показана иерархическая структура дисковой памяти в операционной системе. Каждому диску, или физическому тому (PV), присвоено имя, например, /dev/hdisk0. Все используемые физические тома образуют группы томов (VG). Все физические тома из группы томов разделены на физические разделы (PP) равного размера (по умолчанию - 4 Мб в группе, состоящей из томов размером меньше 4 Гб, и 8 Мб на дисках большего размера).
Для удобства выделения памяти каждый физический том разделен на пять областей. За дополнительной информацией обратитесь к разделу Расположение данных на физическом томе. Число физических разделов в разных областях различно и зависит от общего объема диска.
Рис. 2-5. Размещение данных на жестком диске без зеркальной копии. На рисунке приведен пример физического тома, на основе которого созданы логические тома. В таких разделах физического тома, называемых логическими томами, хранятся файловые системы, представляющие собой структуру файлов и каталогов. Файлы хранятся в блоках дорожек физического носителя. Обычно для файла выделяются несмежные блоки. В результате того, что одни файлы стираются, а другие файлы записываются в освободившиеся блоки, расположенные на разных дорожках носителя, происходит фрагментация диска.
В каждой группе томов определен один или несколько логических томов (LV). Логический том состоит из одного или нескольких логических разделов. Каждому логическому разделу соответствует один или несколько физических разделов. Если для данного логического тома применяется зеркальная защита, то выделяются дополнительные физические разделы для размещения зеркальных копий каждого логического раздела. Хотя нумерация логических разделов последовательная, номера входящих в их состав физических разделов могут быть произвольными.
Логические тома могут служить для различных целей, например, для подкачки, однако для тех из них, которые содержат обычные системные или пользовательские данные, либо программы, есть одна журнализированная файловая система (JFS). Каждая JFS состоит из нескольких блоков пространства подкачки размером 4096 байт. Если нужно записать данные в файл, для этого файла отводится несколько дополнительных блоков. Эти блоки не обязательно должны следовать друг за другом, либо быть смежными с другими блоками файла.
В операционной системе AIX версии 4 можно определить файловую систему с размером фрагмента меньше 4096 байт. Размер фрагмента может составлять 512, 1024 или 2048 байт, что позволяет более эффективно размещать небольшие файлы.
На предыдущем рисунке показана одна из плохих ситуаций (хотя и не худшая из возможных), которые могут возникнуть в нереорганизованной файловой системе. Файл /op/filename физически размещен в большом числе блоков, не смежных друг с другом. При последовательном чтении файла необходимо выполнить огромное количество операций поиска, каждая из которых занимает много времени.
Хотя логически файл в операционной системе представлен как непрерывная строка последовательных байтов, физический файл может мало соответствовать такому представлению. Фрагментация может возникнуть вследствие многократного увеличения логического тома, либо интенсивных операций по выделению, освобождению и повторному выделению памяти в файловой системе. Говорят, что файловая система фрагментирована, если свободное дисковое пространство в ней состоит из множества небольших блоков, не позволяющих записать файл в смежные блоки.
При обращении к файлу в файловой системе с высокой степенью фрагментации может потребоваться большое число операций поиска, а время ответа сильно возрастает (основную часть времени ответа составляют задержки, необходимые для выполнения поиска). Например, для последовательного считывания файла, разбитого на множество разбросанных маленьких фрагментов, потребуется больше операций поиска, чем для последовательного чтения файла, состоящего из одного или нескольких больших непрерывных фрагментов. При прямом доступе к файлу, разбросанному по всему диску, потребуется больше операций поиска, чем в случае, когда блоки файла расположены близко друг к другу.
Влияние фрагментации файла на производительность операций ввода-вывода уменьшается при загрузке файла в буфер оперативной памяти. При открытии файла в операционной системе ему выделяется постоянный сегмент данных в виртуальной памяти. Этот сегмент представляет буфер виртуальной памяти для данного файла; блоки файла непосредственно преобразуются в страницы сегмента. VMM управляет страницами сегмента, считывая блоки файла по мере надобности (т.е. по мере доступа к ним) в страницы сегмента. В некоторых условиях VMM записывает страницу памяти обратно в соответствующий блок файла на диске; однако в общем случае VMM после обращения к странице некоторое время хранит ее в памяти. Следовательно, страницы, к которым часто обращаются, долгое время находятся в памяти, и для доступа к соответствующим блокам не нужно обращаться к физическому диску.
Периодически пользователю или системному администратору следует выполнять реорганизацию распределения файлов по логическим томам и логических томов по физическим томам для снижения уровня фрагментации и более равномерного распределения нагрузки на все устройства ввода-вывода. Глава 8. Отслеживание и настройка использования дисков содержит дополнительную информацию по обнаружению и исправлению ошибок, связанных с размещением файлов и фрагментацией.
Наблюдая за тем, в какой последовательности программа обрабатывает компоненты файла при последовательном доступе, VMM пытается заранее считать нужные страницы в память. Если программа последовательно обращается к двум расположенным одна за другой страницам файла, VMM предполагает, что программа и в дальнейшем будет последовательно обрабатывать файл, и выполняет дополнительные операции последовательного чтения файла. Эти операции чтения выполняются одновременно с программой, в результате чего данные становятся доступны программе раньше, чем если бы VMM начинал операции ввода-вывода только после того, как программа обратится к следующей странице. Количество страниц, считываемых заранее, определяется двумя параметрами VMM:
Если программа прекращает последовательную обработку файла и обращается не к следующей по порядку странице, процесс последовательного опережающего чтения прекращается. Если VMM обнаружит, что программа вернулась к последовательному чтению данных, процесс начнется снова, и в первый раз будет считано minpgahead страниц. Значения minpgahead и maxpgahead можно изменить с помощью команды vmtune. Дополнительную информацию об упреждающем чтении и основные правила изменения пороговых значений можно найти в разделе Упреждающее чтение при последовательном доступе.
Для повышения производительности записи, ограничения количества ожидающих выгрузки страниц в памяти, снижения общей нагрузки на систему и фрагментации диска файловая система делит каждый файл на разделы по 16 Кб. Страницы, относящиеся к данному разделу, не записываются на диск до того, как программа запишет первый байт следующего раздела длиной 16 Кб. В этот момент система принудительно записывает на диск четыре ожидающих выгрузки страницы из первого раздела. Страницы с данными остаются в памяти до тех пор, пока не поступит повторный запрос к соответствующим страницам физической памяти. Для обработки этого запроса не потребуется выполнять дополнительных операций ввода-вывода. Если программа обращается к любой из страниц до этого момента, операции ввода-вывода не выполняются.
Если в памяти находится большое количество уже обработанных страниц, и повторно к ним не обращаются, демон sync записывает их на диск, что может привести к резкому возрастанию интенсивности операций с диском. Для более равномерного распределения операций ввода-вывода можно включить механизм опережающей записи, указав системе, сколько страниц может храниться в памяти без записи на диск. Пороговое значение для числа страниц, хранящихся в памяти без записи на диск, задается отдельно для каждого файла, поэтому страницы записываются на диск до запуска демона sync. В результате операции ввода-вывода будут распределены более равномерно.
Существуют два алгоритма опережающей записи: последовательный и случайный. Размер разделов и величину порога для опережающей записи можно задать с помощью команды vmtune (см. раздел Опережающая запись страниц VMM).
Обычные файлы автоматически преобразуются в сегменты памяти. Это означает, что при обращении к файлу не выполняется обычная буферизация ядра и процедуры ввода-вывода блоков, что позволяет файлам использовать больший объем памяти при ее достаточном количестве (кэш файла может выйти за пределы объявленной области буферов ядра).
Файлы можно преобразовать явно с помощью функции shmat() или mmap(), однако при этом для кэша не будет доступен дополнительный объем памяти. Приложения, явно преобразующие файлы с помощью функций shmat() и mmap(), и обращающиеся к ним по адресу, а не с помощью функций read() и write(), могут не указывать длинные пути к файлам в системных вызовах, но не могут использовать функцию опережающей записи.
Если приложение не применяет функцию write(), то измененные страницы накапливаются в памяти, а затем алгоритм замены страниц VMM или демон sync записывает их на диск случайным образом. В результате выполняется много небольших операций записи на диск, что снижает эффективность использования ресурсов процессора и диска, а также повышает степень фрагментации, что в будущем негативно скажется на скорости чтения файла.
Так как большинство операций записи выполняется асинхронно, размер очередей в буферах ввода-вывода может достигать нескольких мегабайт, а выполнение операций может занимать несколько секунд. Производительность интерактивного приложения значительно снижается, если при выполнении каждой операции чтения с диска несколько секунд уходит на обработку очереди. Для решения этой проблемы в VMM предусмотрены параметры, задающие ограничение на ввод-вывод, которые предназначены для управления операциями записи.
Ограничение ввода-вывода никак не влияет ни на интерфейс, ни на логическую схему ввода-вывода. Это просто ограничение количества операций ввода-вывода, помещаемых в буфер. Если для какого-либо процесса количество таких операций превышает установленное предельное значение, процесс приостанавливается до тех пор, пока число необработанных запросов не достигнет нижней границы. Более подробная информация об ограничении ввода-вывода приведена в разделе Применение ограничения дискового ввода-вывода.