Как и для любой сложной системы, для обеспечения работы многопроцессорной системы с высокой производительностью нужно создать специальную конфигурацию. По сравнению с однопроцессорными компьютерами, в такой системе применяется более сложное программное и аппаратное обеспечение, которое предоставляет дополнительные возможности, но требует приложить дополнительные усилия для обеспечения согласованности. Поскольку можно предложить различные варианты конфигурации многопроцессорной системы, каждая из которых имеет свои преимущества, существует множество разнообразных архитектур многопроцессорных систем.
В этом разделе приведены основные правила создания многопроцессорных систем и описано, каким образом эти правила учтены в реальных системах.
Существует несколько типов многопроцессорных систем (MP). Они описаны ниже:
Каждый процессор представляет собой автономный компьютер, на котором запущена своя копия операционной системы. У процессоров нет общих ресурсов (то есть у каждого из них есть своя оперативная память, кэши и диски), однако они соединены между собой. Если они соединены с помощью локальной сети, то говорят, что процессоры слабо связаны между собой. Если они соединены при помощи коммутатора, то говорят, что процессоры сильно связаны. Процессоры взаимодействуют друг с другом путем передачи сообщений.
К достоинствам таких систем относят возможность масштабируемости и высокий коэффициент готовности. Недостатком таких систем является то, что в них необходимо использовать особую модель программирования (с передачей сообщений).
У процессоров есть собственная оперативная память и кэш. Все процессоры работают параллельно и используют общие диски. Каждый процессор работает со своей копией операционной системы и слабо связан с остальными процессорами (процессоры соединены с помощью локальной сети). Процессоры взаимодействуют друг с другом путем передачи сообщений.
К достоинствам архитектуры с общими дисками относится возможность использовать часть стандартной модели программирования (данные на диске доступны и согласованы, данные в оперативной памяти - нет) и высокий коэффициент готовности, которого намного проще достигнуть, чем в системах с общей оперативной памятью. Недостатком является ограниченная масштабируемость из-за сложностей в организации физического и логического доступа к общим данным.
У всех процессоров в кластере с общей оперативной памятью есть собственные ресурсы (оперативная память, диски и устройства ввода-вывода), и на каждом из них работает своя копия операционной системы. Процессоры сильно связаны между собой (соединены через коммутатор). Процессоры взаимодействуют друг с другом через общую память.
Все процессоры расположены в одном корпусе и сильно связаны между собой с помощью высокоскоростной шины или коммутатора. Процессоры совместно работают с глобальной оперативной памятью, дисками и устройствами ввода-вывода. На всех процессорах работает одна и та же копия операционной системы, поддерживающая такую архитектуру (операционная система с поддержкой нескольких нитей).
У SMP есть несколько достоинств:
При работе с системами SMP следует учитывать следующие ограничения:
Все многопроцессорные системы можно разделить на две основные группы: асимметричные и симметричные.
В асимметричных многопроцессорных системах процессоры выполняют разные роли. Один процессор может отвечать за операции ввода-вывода, другие - выполнять пользовательские программы и т.д. Обычно один процессор является главным, а остальные - подчиненными. Главный процессор выполняет задачи общего характера, операции ввода-вывода и вычисления. Подчиненные процессоры предназначены только для решения вычислительных задач. Если главный процессор медленно обрабатывает запросы подчиненных процессоров, то эффективность работы подчиненных процессоров будет низкой. Задания с большим количеством операций ввода-вывода могут выполняться медленно, поскольку вводом-выводом занимается только главный процессор. Сбой главного процессора приводит к сбою всей системы. Вот некоторые достоинства и недостатки такой конфигурации:
В симметричной многопроцессорной системе все процессоры одинаковые и выполняют идентичные функции:
Такая взаимозаменяемость означает, что любой процессор потенциально может выполнять любую ожидающую выполнения операцию. С отрицательными аспектами такой гибкости сталкиваются в основном разработчики аппаратного и программного обеспечения, хотя в симметричных системах накладываются наиболее сильные ограничения на многопроцессорную обработку.
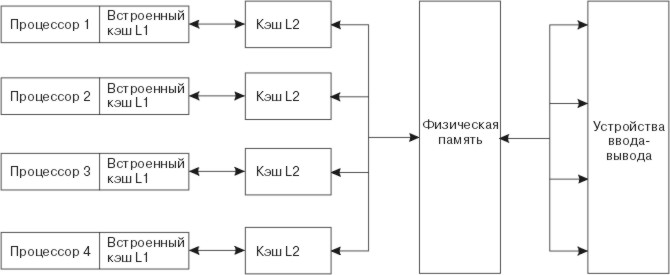
Операционная система AIX версии 4 поддерживает только симметричные многопроцессорные системы, одна из которых показана на следующем рисунке. В разных системах применяется разная конфигурация кэш-памяти.
Рис. 3-1. Стандартная симметричная многопроцессорная система. На рисунке показано четыре корпуса, каждый из которых содержит процессор с собственным кэшем первого уровня. Из кэша L1 данные передаются в кэш второго уровня, выделенный процессору. Кэш L2 может обмениваться данными с оперативной памятью. Кроме того, данные из этого кэша могут быть переданы для обработки устройствам ввода-вывода.
Хотя аппаратная конфигурация многопроцессорных систем симметрична, ее программное обеспечение обладает некоторой асимметрией. В процессе запуска управление изначально принадлежит одному процессору. Этот процессор является главным. Не следует путать его с главным процессором в асимметричной архитектуре. Этим термином обозначается всего лишь процессор по умолчанию. Главный процессор задается переменной MP_MASTER в файле /usr/include/sys/processor.h. В настоящий момент ее значение равно 0.
Для того чтобы в многопроцессорной системе работали программы, созданные пользователями в однопроцессорной системе, необходимо переместить на главный процессор те драйверы устройств и расширения ядра, для которых явным образом не указана совместимость с многопроцессорной средой. Это ограничение называется funnelling.
В системе SMP приложение можно распараллелить двумя способами:
При выборе способа распараллеливания приложения необходимо сравнить достоинства нитей и процессов. Нити могут выполняться быстрее процессов и, кроме того, при работе с нитями легче организовать доступ к общей памяти. С другой стороны, программу, разбитую на несколько процессов, проще распределить по нескольким компьютерам или кластерам. Если в ходе работы приложения создаются и удаляются новые экземпляры, то реализация с помощью нитей будет работать быстрее, так как для порождения процесса потребуется меньше ресурсов. Во всех остальных случаях реализации с помощью процессов и нитей будут сравнимы по своей эффективности.
Любой объект, доступный для чтения или записи нескольким нитям, может быть изменен во время работы программы. Обычно это правило справедливо и для многопрограммных сред, однако в многопроцессорных системах оно имеет особое значение по двум причинам:
Примечание: Во избежание ошибок, программы, работающие с общими данными, должны обращаться к ним последовательно, а не параллельно. Перед записью данных необходимо защитить эти данные на время выполнения операции от изменения другими программами (в том числе, другим экземпляром той же программы). Операции чтения обычно могут выполняться параллельно.
Главный механизм, позволяющий избежать конфликтов между программами - блокировка. Блокировкой называется разрешение на доступ к одному или нескольким элементам данных. Запросы на блокировку и разблокирование являются элементарными, то есть во время их выполнения управление не передается другим нитям. Перед обращением к общему объекту программа должна установить блокировку этого объекта. Если другая программа, либо другая нить той же программы, уже установила блокировку объекта, то запрашивающей программе придется дождаться освобождения объекта.
Время простоя нити увеличивается не только за счет ожидания блокировки, но и за счет сериализации доступа к данным. Во время простоя нити другие нити могут заменить в кэше данные первой нити на свои. В результате, когда исходная нить сможет установить блокировку и получит управление, ее производительность снизится за счет увеличения длительности операций ввода-вывода.
Многие общие объекты данных расположены в ядре операционной системы, поэтому в ядре выполняется внутренняя сериализация. Это означает, что задержка из-за сериализации доступа может возникнуть даже в том случае, когда приложение не работает с общими данными, но применяет службы ядра, которые работают с общими данными ядра.
При создании функций блокировки операционной системы AIX версии 4, применяемых при работе в многопроцессорных системах, за основу была взята модель блокировок OSF/1 версии 1.1. Но поскольку в операционной системе применяется подкачка страниц и вытеснение нитей, к модели блокировок OSF/1 1.1 были добавлены некоторые новые функции. Простые и сложные блокировки являются вытесняющими. Кроме того, в ожидании освобождения простой блокировки нить может быть приостановлена, если владелец этой блокировки в настоящий момент не выполняется. Также простые блокировки преобразуются, если процессор ожидает освобождения блокировки в течение определенного периода времени (этот период задается одной из системных переменных).
В операционной системе версии 4 под простой блокировкой понимается блокировка с ожиданием из-за занятости. Если какая-либо нить ожидает снятия простой блокировки, то, при выполнении определенных условий, эта нить будет приостановлена. Таким образом, нить не будет ждать снятия блокировки бесконечно. Простые блокировки являются вытесняющими. Это означает, что нить ядра, установившая простую блокировку, может быть вытеснена другой нитью ядра с более высоким приоритетом. В многопроцессорных системах простые блокировки применяются для управления доступом нитей в критические секции. Они должны использоваться вместе со средствами управления прерываниями для сериализации выполнения на текущем процессоре и взаимодействия между процессорами.
В однопроцессорной системе достаточно использовать только прерывания. Блокировки в ней не нужны. Простые блокировки предназначены для защиты критических секций типа нить-нить и нить-прерывание. Нить будет ожидать установления простой блокировки до тех пор, пока ресурс не освободится. Различают два состояния простой блокировки: заблокировано и разблокировано.
В операционной системе AIX версии 4 сложные блокировки представляют собой блокировки чтения-записи, защищающие критические секции, к которым могут обращаться несколько нитей. Такие блокировки являются вытесняющими. Сложные блокировки представляют собой блокировку с ожиданием из-за занятости. Это означает, что нить, ожидающая возможности установить блокировку, в некоторых случаях приостанавливается. По умолчанию такие блокировки не являются рекурсивными. Для работы с рекурсивными блокировками нужно вызвать службу ядра lock_set_recursive(). У таких блокировок есть три состояния: исключительная блокировка на запись, общая блокировка с разрешением чтения и разблокирована.
Программист, работающий с многопроцессорной системой, должен решить, сколько отдельных блокировок потребуется установить для доступа к общим данным. Если изменяется несколько элементов большого набора данных, то можно установить блокировку на уровне всего набора, но в этом случае возрастает вероятность конфликтов с другими нитями. Широкое использование блокировок накладывает ограничение на производительность системы.
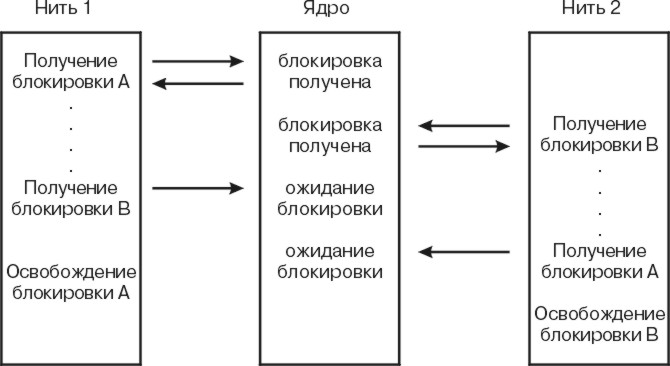
Можно установить отдельную блокировку для каждого элемента. В этом случае вероятность конфликта с другими нитями достаточно мала. Однако обработка каждого запроса на блокировку и разблокирование занимает процессорное время. Кроме того, при большом числе блокировок может возникнуть тупик. Простейший пример тупика показан на следующем рисунке. Здесь нить 1 установила блокировку A и ожидает снятия блокировки B, которую установила нить 2. В то же время, нить 2 ожидает освобождения блокировки A. Выполнение ни одной из программ не достигнет вызова unlock(), поэтому они будут находиться в тупике бесконечно. Для того чтобы избежать тупиков, обычно задаются правила, определяющие последовательность захвата объектов программами, работающими с этими данными.
Рис. 3-2. Тупик. На следующем рисунке показан пример тупика. Нить 1 установила блокировку A и ожидает освобождения блокировки B, которую установила нить 2. В то же время, нить 2 ожидает освобождения блокировки A. Выполнение ни одной из программ не достигнет вызова unlock, поэтому они будут находиться в тупике вечно.
Согласно теории организации очередей, чем меньше простаивает ресурс, тем больше среднее время ожидания этого ресурса. Эта зависимость не линейная. Если время блокировки увеличится вдвое, то среднее время ожидания снятия этой блокировки увеличится больше чем вдвое.
Самый эффективный способ сократить время ожидания снятия блокировки заключается в снижении уровня объектов, для которых можно установить блокировку. Ниже приведены некоторые рекомендации:
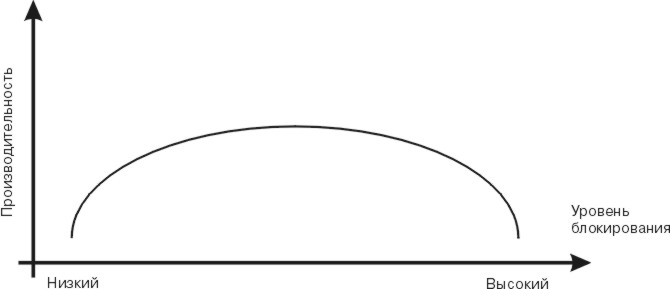
С другой стороны, блокировка на очень низком уровне приведет к увеличению запросов на установление и снятие блокировок, что приведет к увеличению сложности программ. Необходимо выбрать золотую середину между слишком низким и слишком высоким уровнями блокировки. Оптимальный уровень блокировок можно найти только путем проб и ошибок. Это одна из самых сложных задач, возникающих при работе с многопроцессорной системой. Приведенная ниже диаграмма показывает взаимосвязь между производительностью системы и уровнем блокировок.
Рис. 3-3. Взаимосвязь между производительностью системы и уровнем блокировок. На этом рисунке показана двумерная диаграмма. По вертикальной оси (y) откладывается значение производительности. Горизонтальная ось (x) представляет уровень блокировок. Взаимосвязь между уровнем блокировок и производительностью представлена в виде выпуклой кривой. С увеличением уровня блокировок производительность вначале растет до максимума, а затем начинает медленно снижаться. Из этого следует, что для достижения максимальной производительности нужно выбрать оптимальный уровень блокировок.
Запросы и ожидание блокировок, а также разблокирование объектов создают дополнительную нагрузку на процессор:
Если нить должна захватить блокировку, которая в настоящий момент занята, то она будет ожидать освобождения блокировки. Есть два варианта ожидания снятия блокировки:
Ожидание снятия блокировки всегда влияет на производительность системы. В случае блокировок с ожиданием из-за занятости процессор не освобождается, несмотря на то, что он не выполняет полезной работы (это приводит к снижению производительности). В случае блокировок с выгрузкой из-за занятости переключение контекста и повторная постановка в очередь выполнения создает дополнительную нагрузку на систему. Помимо этого, возрастает число промахов в кэше.
Разработчики операционной системы могут выбрать один из двух типов блокировок: взаимно исключающие простые блокировки, позволяющие процессам ожидать снятия блокировки в активном состоянии, либо сложные блокировки чтения-записи, выгружающие процессы, которые ожидают снятия блокировки.
Существуют определенные соглашения относительно использования блокировок. Ни аппаратных, ни программных способов активизации или проверки состояния блокировок не существует. Хотя за счет блокировок операционная система AIX версии 4 обеспечивает согласованную работу многопроцессорной системы, разработчики должны самостоятельно определять и реализовывать стратегию блокировки для защиты собственных глобальных данных.
При создании многопроцессорных систем большое внимание уделяется проблеме согласованности кэша. Эта проблема была решена за счет некоторого снижения производительности системы. Для того чтобы понять, почему это так, необходимо разобраться в сути проблемы:
Если у каждого процессора есть кэш, содержащий некоторые данные из памяти, то сразу несколько кэшей могут содержать одинаковую строку данных. Кроме того, эта строка может содержать сразу несколько блокируемых элементов данных. Если две нити последовательно изменят эти элементы данных, то в кэшах могут оказаться разные версии этой строки памяти. Это означает, что целостность системы будет нарушена, так как в ней будут хранится две версии содержимого определенной области памяти.
Обычно для решения проблемы согласованности кэша все копии строки памяти, кроме одной, объявляются неверными. Это выполняется специальной контрольной логической схемой на аппаратном уровне без участия программного обеспечения. Однако в результате при следующем обращении к неверной строке кэша произойдет промах и возникнет связанная с ним задержка.
Контрольная логическая схема применяется для решения задач, связанных с поддержанием согласованности кэша. При изменении записи кэша эта логическая схема процессора рассылает оповещающее сообщение по шине. Кроме того, эта логическая схема отслеживает подобные сообщения, отправленные по шине другими процессорами.
Когда процессор обнаруживает, что другой процессор изменил запись с адресом, который есть в его собственном кэше, контрольная логическая схема объявляет эту запись неверной. Такая процедура называется перекрестным аннулированием. В ходе перекрестного аннулирования процессору сообщается, что запись в кэше не верна, поэтому ее нужно взять из памяти или другого кэша. Поскольку перекрестное аннулирование увеличивает число промахов в кэше, а протокол контрольной логической схемы увеличивает нагрузку на шину, то поддержание кэша в согласованном состоянии снижает производительность и масштабируемость SMP.
Когда выполнение нити прерывается, а позднее вновь возобновляется на том же процессоре, то в кэше все еще могут находится данные этой нити. Если работа нити возобновляется на другом процессоре, то произойдет ряд промахов кэша, пока данные этой нити не будут записаны в кэш процессора из оперативной памяти или кэша другого процессора. С другой стороны, еще большая задержка может возникнуть в том случае, если нити придется ждать, пока освободится исходный процессор.
Принадлежностью процесса процессору называется свойство, гарантирующее, что работа нити всегда возобновляется на том же процессоре, на котором она выполнялась раньше. Ценность этого свойства прямо пропорциональна объему данных нити, хранящихся в кэше, и обратно пропорциональна времени простоя нити. Планировщик операционной системы AIX версии 4 по умолчанию применяет это свойство для всех процессоров.
Говорят, что нить связана с определенным процессором, если нить полностью принадлежит процессору. Связывание означает, что нить будет выполняться только заданным процессором, независимо от загруженности других процессоров системы. Команда bindprocessor и процедура bindprocessor() позволяют связать все нити процесса с определенным процессором (см. раздел Команда bindprocessor). Связь с процессором, установленная явным образом, наследуется дочерними процессами, созданными с помощью системных вызовов fork() и exec().
Связывание может эффективно применяться в программах с большой нагрузкой на процессор и небольшим числом прерываний. Однако иногда связывание может послужить причиной снижения производительности, так как нити придется ждать освобождения процессора после выполнения операции ввода-вывода. Если нить была заблокирована на время выполнения операции ввода-вывода, то маловероятно, что информация о ней сохранилась в кэше процессора. В этом случае продолжение работы нити на другом процессоре было бы эффективнее.
В однопроцессорной системе задержки, связанные с конкуренцией за внутренние ресурсы (устройства памяти, шины ввода-вывода и памяти), обычно невелики. В многопроцессорных системах эти задержки становятся ощутимыми, особенно в том случае, если применяется алгоритм поддержания согласованности кэша, который увеличивает число обращений к оперативной памяти.