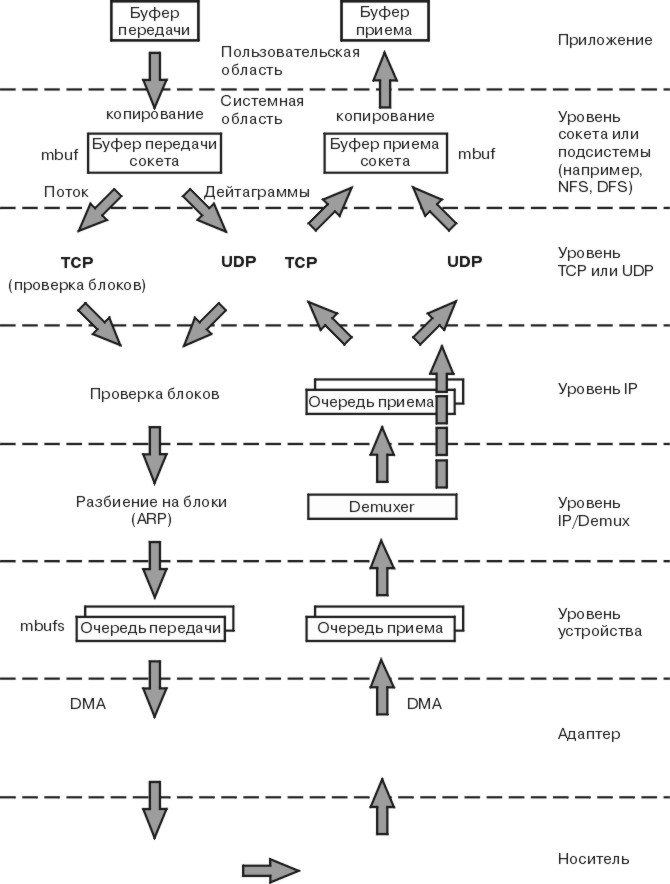
Для того чтобы понять, какими особенностями с точки зрения производительности обладают протоколы UDP и TCP/IP, необходимо знать принципы работы этих протоколов. На приведенном ниже рисунке показана структура, обсуждаемая в данном разделе.
Рис. 9-1. Схема передачи данных в UDP и TCP/IP. На рисунке показана передача данных от приложения в одной системе приложению в удаленной системе. Различные уровни передачи данных описаны ниже.
На рисунке показана передача данных от приложения в одной системе приложению в удаленной системе. В данной главе подробно описаны действия, выполняемые на каждом уровне. Ниже приведено их краткое описание:
Для того чтобы избежать фрагментации памяти ядра и отправки излишних вызовов xmalloc(), различные уровни подсистемы связи работают с общими пулами буферов. Функция управления mbuf работает с буферами разных размеров. Для пулов выделены закрепленные страницы памяти ядра, то есть страницы виртуальной памяти, которые никогда не выгружаются на диск. В результате объем физической памяти, который может применяться приложениями для хранения данных и подкачки, уменьшается на размер пулов mbuf.
Общие пулы mbuf и кластеров позволяют не только избежать дублирования данных, но и передавать указатели между уровнями подсистемы связи напрямую, сокращая число вызовов управляющих команд и операций копирования данных.
За дополнительной информацией обратитесь к разделу Повышение эффективности работы с пулом mbuf.
Сокеты предоставляют интерфейс прикладных программ (API) для работы с подсистемой связи. Существует несколько типов сокетов, применяющих разные протоколы связи и предоставляющих разные типы сервиса. Сокеты типа SOCK_DGRAM используют протокол UDP. Сокеты типа SOCK_STREAM используют протокол TCP.
К сокету применимы операции открытия, чтения и записи, аналогичные операциям, которые выполняются над файлами.
Общий размер буферов в виртуальной памяти системы, применяемых сокетами для приема и передачи данных (то есть общий размер пулов mbuf в байтах), ограничен следующими системными значениями (значения по умолчанию, применяемые в качестве ограничений, можно изменить для отдельных сокетов с помощью функции setsockopt()):
Для просмотра этих значений вызовите следующую команду:
# no -a
Пользователь root может изменить эти значения с помощью следующей команды:
# no -o udp_sendspace=новое-значение
Новое-значение должно быть не больше параметра sb_max, задающего максимальный объем памяти, который может быть выделен для буферов приема и передачи сокета. Значение параметра sb_max, применяемое по умолчанию, зависит от версии операционной системы и объема физической памяти. Текущее значение sb_max можно узнать с помощью команды no -a. Для того чтобы изменить это значение, вызовите команду no в следующем формате:
# no -o sb_max=новое-ограничение
Примечание: Размер буферов приема и передачи сокета ограничен значением sb_max, так как sb_max задает максимальный объем памяти, который может быть выделен для буферов. Тем не менее, эти два параметра задают разные величины. Размер буфера сокета ограничивает объем данных, которые могут быть помещены в этот буфер. Значение sb_max ограничивает объем памяти mbuf, который может быть выделен буферу сокета. Например, в сети Ethernet кластер mbuf размером 2048 байт может содержать не более 1500 байт данных. В этом случае значение sb_max должно быть в 1,37 раз больше указанного размера буфера сокета. Рекомендуется, чтобы значение sb_max было как минимум в два раза больше размера самого большого буфера сокета.
После того как приложение записывает данные в сокет, уровень сокета вызывает транспортный уровень (TCP или UDP), который копирует данные из пользовательского пространства в буфер передачи сокета, расположенный в области памяти ядра. В зависимости от размера данных, скопированных в буфер передачи сокета, эти данные помещаются в структуры mbuf или кластеры.
Приложение, расположенное в системе-получателе, открывает сокет и пытается считать из него данные. Если в буфере приема нет данных, уровень сокета переводит нить приложения в состояние ожидания (блокирует нить) до появления данных. После получения данных они помещаются в очередь буферов приема сокета, а нить освобождается. Затем данные копируются в буфер приложения, расположенный в пользовательском пространстве, структуры mbuf освобождаются, а управление передается приложению.
В AIX 4.3.1 и выше значение sockthresh ограничивает объем памяти подсистемы связи, который может быть выделен для сокетов. После достижения этого ограничения создавать сокеты запрещается. Значение параметра sockthresh указывается в процентах от значения thewall. Значение по умолчанию равно 85 процентам. Допустимы значения от 1 до 100. Размер sockthresh должен быть не меньше размера памяти, используемой в данный момент.
Настройка ограничения sockthresh позволяет предотвратить ситуацию, когда вся память подсистемы связи будет занята существующими соединениями. Если память будет переполнена, компьютер может зависнуть, и для продолжения работы потребуется перезагрузка. Укажите в параметре sockthresh пороговое значение, при достижении которого создание сокетов должно быть запрещено. После достижения указанного порогового значения вызовы функций socket() и socketpair() будут возвращать код ошибки ENOBUFS, а все поступающие запросы на установление соединения будут игнорироваться. Это позволит продолжить работу существующим соединениям и предотвратит сбой системы.
Каждый раз, когда приложению не удается создать сокет из-за того, что было достигнуто ограничение sockthresh, увеличивается число сокетов, не созданных из-за достижения порога sockthresh, которое можно просмотреть с помощью команды netstat -m.
Для просмотра значения sockthresh вызовите следующую команду:
# no -o sockthresh
Пользователь root может изменить пороговое значение с помощью следующей команды:
# no -o sockthresh=новое-значение
Значение по умолчанию можно установить с помощью следующей команды:
# no -d sockthresh
Нефиксированным портом называется порт, выделяемый в ответ на запрос приложения, в котором не указан конкретный номер порта. В версиях AIX младше 4.3.1 диапазон номеров таких портов составляет от 1024 до 5000. В AIX 4.3.1 и выше по умолчанию диапазон номеров нефиксированных портов составляет от 32768 до 65535.
С помощью команды no можно изменить значения параметров tcp_ephemeral_low и tcp_ephemeral_high, задающих диапазон номеров нефиксированных портов. Максимальный диапазон может составлять от tcp_ephemeral_low=1024 до tcp_ephemeral_high=65535. Для портов UDP аналогичные значения можно задать с помощью параметров udp_ephemeral_low и udp_ephemeral_high (по умолчанию применяются те же значения, что и для TCP).
Два следующих раздела описывают функции UDP и TCP. Для того чтобы упростить сравнительный анализ UDP и TCP, оба описания поделены на разделы с информацией о соединении, обнаружении ошибок, исправлении ошибок, управлении потоком, размере данных и применении MTU.
Протокол UDP может применяться приложениями, в которых предусмотрены функции обработки ошибок связи. Применение такого протокола не требует значительных затрат ресурсов. Обычно UDP применяется в приложениях, работающих по схеме вопрос-ответ. Поскольку такие приложения все равно вынуждены обрабатывать ошибки, для того чтобы отправить ответ даже в случае сбоя, они обрабатывают и ошибки связи. В связи с этим подсистемы NFS, ONC RPC, DCE RPC и DFS применяют протокол UDP.
Ниже перечислены некоторые особенности протокола UDP:
Если значение udp_sendspace больше размера дейтаграммы, то данные приложения копируются в структуры mbuf, расположенные в области памяти ядра. Если размер дейтаграммы превышает udp_sendspace, приложению возвращается сообщение об ошибке.
Операционная система выбирает два буфера оптимального размера. Например, данные размером 8704 будут скопированы в два кластера размером 8192 и 512 байт. После этого UDP добавляет заголовок UDP (по возможности в ту же структуру mbuf), вычисляет контрольную сумму и вызывает функцию IP ip_output().
UDP проверяет контрольную сумму и помещает данные в очередь соответствующего сокета. Если при этом будет превышено ограничение udp_recvspace, то пакет отбрасывается. Число отброшенных пакетов можно узнать с помощью команды netstat -s. Оно указывается в поле число переполнений буфера сокета в разделе udp:. Если приложение ожидает получения данных из сокета, оно помещается в очередь вывода. В результате дейтаграмма копируется в пользовательское адресное пространство, а буферы mbuf освобождаются. Обычно получатель отправляет отправителю подтверждение о получении данных и ответное сообщение.
В AIX 4.1.1 и выше UDP вычисляет контрольную сумму динамически при копировании данных в структуру mbuf ядра. При получении данных может применяться такой же способ вычисления контрольной суммы, однако для этого приложение должно указать опцию SO_CKSUMRECV в вызове функции setsockopt(). Эту опцию рекомендуется установить в тех приложениях, которые применяют UDP для получения данных большого объема.
TCP - это надежный протокол передачи данных. TCP подходит приложениям, значительная часть работы которых связана с передачей или получением данных. Так как TCP гарантирует доставку пакета от отправителя к получателю, приложение освобождается от необходимости обнаруживать и исправлять ошибки. Примерами приложений, применяющих TCP, могут служить ftp, rcp и telnet. При соответствующей настройке DCE также может работать на основе TCP.
Ниже перечислены некоторые особенности протокола TCP:
Рис. 9-2. Скользящее окно TCP. На этом рисунке проиллюстрирован алгоритм применения скользящего окна TCP. Его описание приведено под рисунком.
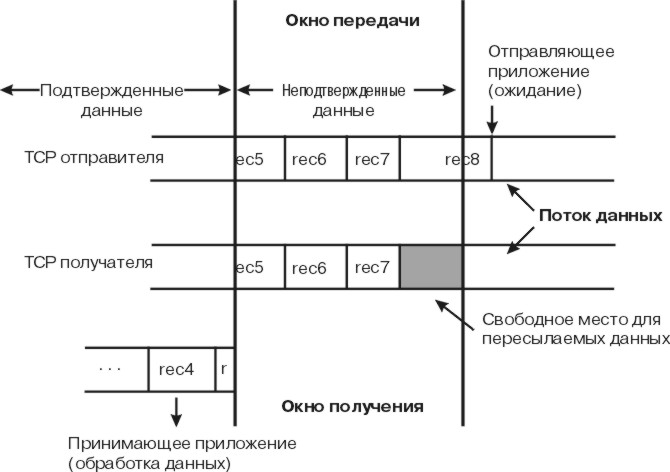
На этом рисунке приложение, отправляющее данные, находится в состоянии ожидания, поскольку буфер отправки сокета TCP переполнен (то есть достигнуто ограничение tcp_sendspace). Передающий уровень TCP содержит последнюю часть записи 5, записи 6 и 7 полностью и начало записи 8. Принимающий уровень TCP еще не получил последнюю часть записи 7 и запись 8. Принимающее приложение получило запись 4 и часть записи 5 во время последнего чтения данных из буфера сокета и теперь обрабатывает принятые данные. При следующим чтении данных из буфера сокета (предполагается, что будет считан достаточный объем данных) приложение получит остальную часть записи 5, запись 6 и части записей 7 и 8, которые будут получены к тому моменту.
После этого будут выполнены следующие действия:
Приложение, отправляющее данные, будет активизировано. Для того чтобы избежать передачи лишних данных по сети в случае, когда приложение считывает данные блоками маленького размера, TCP откладывает отправку подтверждения до тех пор, пока объем данных, прочитанных приложением, не составит половины размера окна приема или удвоенного максимального размера сегмента.
Если у получателя нет пакетов, которые нужно передать отправителю, то отправка подтверждения задерживается. Максимальное время задержки составляет 200 мс. После этого подтверждение отправляется отдельным пакетом. Время задержки можно изменить, указав другое значение в параметре fasttimeo команды no. Значение по умолчанию равно 200 мс. Допустимы значения от 50 до 200 мс. Уменьшение задержки позволяет повысить производительность приложений, работающих по схеме вопрос-ответ.
Примечание: Если приложение, работающее по схеме вопрос-ответ, использует TCP для обмена сообщениями, то это приложение должно включить опцию TCP_NODELAY с помощью функции setsockopt(). Это позволит TCP передавать данные немедленно (с учетом ограничений скользящего окна), даже если их размер меньше MTU. Если эта опция останется выключенной, TCP будет ожидать поступления дополнительных данных максимум 200 миллисекунд. В AIX 4.3.3 и выше опцию TCP_NODELAY можно установить для сокетов TCP с помощью параметра tcp_nodelay команды ifconfig или chdev (за дополнительной информацией обратитесь к разделу Параметры сетевого интерфейса (ISNO)).
При настройке сеанса отправитель и получатель обмениваются информацией о размере буфера приема каждой из сторон. На основании этих значений определяется размер окна приема. Данные, записываемые в сокет, помещаются в буфер передачи. Когда получатель сообщает о том, что у него есть свободное пространство в буфере, отправитель передает данные, заполняя все свободное пространство (если у него есть достаточно данных для отправки). Когда целевое приложение отправляет запрос на чтение данных из сокета, сокет возвращает все данные из своего буфера приема. После этого TCP передает отправителю подтверждение о получении пакета и обновляет размер окна приема. Только после этого передающий уровень TCP удаляет данные из своего буфера, сдвигая границу окна вправо на размер доставленных данных. Если окно заполнено данными, так как в целевом приложении возникла ошибка при получении данных, то при попытке записать данные в сокет нить, отправляющая данные, блокируется (или получает особый код ошибки).
Значения tcp_recvspace и tcp_sendspace настраиваются независимо друг от друга. Значение tcp_sendspace определяет размер буфера в ядре отправителя. Значение tcp_recvspace определяет размер буфера получателя и размер окна приема TCP.
Если параметр rfc1323 равен 1, то максимальный размер окна TCP составляет 4 Гб (в противном случае - 64 Кб).
Из-за того что TCP выполняет некоторые дополнительные действия для обеспечения надежности соединения, на его работу затрачивается на 5-10 процентов больше процессорного времени, чем на работу протокола UDP.
Когда уровень TCP получает запрос на запись от сокета, он выделяет структуру mbuf для заголовка и копирует данные в буфер передачи сокета. При этом данные копируются в структуру mbuf заголовка, а если в ней недостаточно места, то выделяется новая цепочка структур mbuf. Если копируемые данные уже находятся в кластерах, реального копирования в новые кластеры не происходит. Вместо этого в заголовке новой структуры mbuf (не путайте этот заголовок с заголовком TCP) размещается указатель на кластеры, содержащие данные. За счет этого система избегает копирования данных блоками по 4 Кб. После этого TCP вычисляет контрольную сумму (если она не вычисляется адаптером PCI), обновляет переменные состояния, применяемые для управления потоком и других целей, а затем вызывает уровень IP и передает ему заголовок mbuf, указывающий на новую цепочку mbuf.
Когда функция приема данных TCP получает данные от уровня IP, выполняются следующие действия:
Протокол IP передает поток дейтаграмм на более высокие уровни. Если ему передается пакет большего размера, чем MTU выбранного интерфейса, он разбивает пакет на фрагменты и передает их приемнику, который собирает их в исходный пакет. Если один из фрагментов теряется при передаче, неполный пакет отбрасывается приемником. В системе можно включить функцию обнаружения MTU маршрута. Эта процедура описана в разделе Настройка максимального размера сегмента TCP.
С помощью параметра ipfragttl можно изменить время ожидания получения фрагмента на уровне IP. Значение этого параметра можно просмотреть и изменить с помощью команды no.
Ниже перечислены значения по умолчанию и диапазоны допустимых значений для
некоторых типов сетей:
| Тип сети | Значение по умолчанию (в байтах) | Диапазон (в байтах) |
| X.25 | 576 | 60-2058 |
| SLIP | 1006 | 60-4096 |
| Обычный Ethernet | 1500 | 60 - 1500 |
| IEEE 802.3 Ethernet | 1492 | 60 - 1492 |
| Гигабитный Ethernet | 9000 (большие кадры) | Нет |
| Token-Ring 4 Мб/с | 1492 | 60 - 4096 |
| Token-Ring 16 Мб/с | 1492 | 60 - 17800 |
| FDDI | 4352 | 1 - 4352 |
| SLA (socc) | 61428 | 1 - 61428 |
| ATM | 9180 | 1 - 65527 |
| HIPPI | 65536 | 60 - 65536 |
| SP Switch | 65520 | 1 - 65520 |
Примечание: В общем случае можно увеличить размер очередей приема и передачи. Это потребует выделения дополнительной памяти, однако позволит избежать некоторых ошибок. За дополнительной информацией обратитесь к разделу Настройка очередей приема и передачи на уровне адаптера.
Когда функция передачи данных IP получает пакет от UDP или TCP, она определяет интерфейс, по которому должна быть отправлена цепочка структур mbuf, обновляет заголовок IP и вычисляет для него контрольную сумму, а затем передает пакет на уровень интерфейса (IF).
IP определяет нужный драйвер устройства и адаптер связи по номеру сети. В таблице интерфейсов драйвера указывается MTU для этой сети. Если размер дейтаграммы меньше размера MTU, IP добавляет заголовок к структуре mbuf, вычисляет для заголовка контрольную сумму и вызывает драйвер для отправки кадра. Если очередь передачи драйвера заполнена, то уровню IP возвращается код ошибки EAGAIN. Этот код ошибки передается UDP, который, в свою очередь, сообщает его приложению, отправляющему данные. Отправитель должен повторить попытку передачи через некоторое время.
Если размер дейтаграммы больше размера MTU (это может произойти только при работе с UDP), то уровень IP разбивает дейтаграмму на фрагменты, размер которых совпадает с MTU, добавляет к каждому фрагменту заголовок IP (в виде mbuf) и по-очереди отправляет кадры путем вызова драйвера. Если очередь передачи драйвера заполнена, он возвращает уровню IP ошибку EAGAIN. IP уничтожает все оставшиеся фрагменты и возвращает EAGAIN уровню UDP. Уровень UDP возвращает EAGAIN передающему приложению. Поскольку протоколы IP и UDP не хранят очередь сообщений, повторная передача должна выполняться приложением.
В AIX версии 4 интерфейсы, как правило, не создают очередь данных, а напрямую обращаются к очереди приема IP для обработки пакета. Циклический интерфейс всегда создает очередь данных. Если очередь данных поддерживается, то принимаемые пакеты помещаются в эту очередь. Если очередь заполнена, то пакеты отбрасываются и не доставляются приложению. Число пакетов, отброшенных на уровне IP, указывается в поле число переполнений ipintrq вывода команды netstat -s. Если это значение увеличивается, настройте параметр ipqmaxlen с помощью команды no.
В AIX версии 4 уровень интерфейса (раньше называвшийся уровнем IF) вызывает IP в нити прерывания. Процедура IP проверяет контрольную сумму заголовка IP и определяет, предназначается ли пакет этой системе. Если это так, и кадр не является фрагментом пакета, уровень IP передает цепочку mbuf процедуре TCP или UDP.
Если полученный кадр является фрагментом крупной дейтаграммы (это может произойти только при работе с UDP), то IP сохраняет кадр. После получения остальных фрагментов они объединяются в логическую дейтаграмму и передаются UDP. Время хранения фрагментов неполной дейтаграммы на уровне IP ограничено значением ipfragttl (его можно изменить с помощью команды no). По умолчанию интервал ipfragttl составляет 30 секунд (параметр ipfragttl равен 60). При потере фрагмента, например, из-за ошибок передачи, отсутствия свободного пространства в mbuf или переполнения очереди передачи, IP его никогда не получит. По истечении интервала ipfragttl IP уничтожает фрагменты незаконченной дейтаграммы. Информацию об этом можно получить с помощью команды netstat -s. Соответствующее значение указывается в поле число фрагментов, отброшенных по тайм-ауту в разделе ip:.
В AIX версии 4 уровень интерфейса (IF), применяемый при отправке данных, соответствует уровню разборки пакета, применяемому при приеме данных. Этот уровень отправляет запросы в очередь передачи драйвера устройства сетевого интерфейса. Вы можете изменить размер очереди передачи, как описано в разделе Настройка очередей передачи и приема на уровне адаптера.
Когда уровень интерфейса получает пакет от уровня IP, он добавляет заголовок уровня канала связи в начало пакета, проверяет, что формат mbuf поддерживается драйвером устройства, и вызывает функцию записи драйвера устройства.
На этом уровне применяется Протокол преобразования адресов (ARP). ARP преобразует 32-разрядный IP-адрес в 48-разрядный аппаратный адрес.
В AIX версии 4 уровень интерфейса получает пакет от драйвера устройства и вызывает IP в нити прерывания для обработки полученных данных.
Если адаптер поддерживает применение нитей (за дополнительной информацией обратитесь к разделу Применение нитей на уровне адаптеров LAN), то полученный пакет помещается в очередь нити, которая вызывает соответствующую функцию IP, TCP или сокета.
Операционная система поддерживает различные адаптеры локальной сети.
В связи с этим систему можно подключить к сетевым интерфейсам разных
типов. Как видно из приведенной ниже таблицы, интерфейсы поддерживают
разную скорость передачи данных, от которой зависит производительность.
| Название | Скорость передачи данных |
| Ethernet (en) | 10 Мбит/с - несколько Гб/с |
| IEEE 802.3 (et) | 10 Мбит/с - несколько Гб/с |
| Token-Ring (tr) | 4 или 16 Мбит/с |
| Протокол X.25 (xt) | 64 Кб/с |
| SLIP (sl) | 64 Кб/с |
| циклический интерфейс (lo) | Нет |
| FDDI (fi) | 100 Мбит/c |
| SOCC (so) | 220 Мбит/с |
| ATM (at) | Несколько сотен Мбит/с (несколько Гб/c) |
Информация об установке адаптеров, ограничении на число адаптеров и оптимальном числе адаптеров приведена в книгах PCI Adapter Placement Reference и RS/6000 Systems Handbook.
В некоторых компьютерах к основной шине PCI подключены дополнительные шины PCI. Некоторые адаптеры со средней и высокой скоростью передачи данных работают медленнее, если они подключены к дополнительной шине, а некоторые адаптеры вообще не рекомендуется подключать к дополнительной шине. В число компьютеров с дополнительными разъемами PCI входят системы E30, F40 и многопроцессорные системы SP 332 МГц.
Адаптеры различаются не только по протоколу связи и среде передачи данных, которые они поддерживают, но и по способу подключения к шине ввода-вывода и процессору. Аналогично, драйверы устройств отличаются способами передачи данных между памятью и адаптером. Ниже описана общая схема приема и передачи данных, применяемая большинством адаптеров.
На уровне драйвера устройства цепочка структур mbuf, содержащих пакет, помещается в очередь передачи. Максимальное число буферов передачи, которые могут быть помещены в очередь, определяется параметром xmt_que_size. В ряде случаев данные копируются в принадлежащие драйверу буферы DMA. После этого адаптеру передается команда для начала работы с DMA.
Затем управление возвращается функции передачи TCP или UDP, которая передает следующий блок данных (если он есть). Когда все данные переданы, управление возвращается приложению, которое продолжает работать параллельно с адаптером, передающим данные. Некоторые адаптеры после окончания передачи отправляют прерывание системе. В результате вызываются функции обработки прерывания устройства, которые обновляют очередь передачи и освобождают буферы mbuf, содержащие отправленные данные.
После того как адаптер получит кадры, он передает их в очередь приема драйвера. Очередь приема может состоять из структур mbuf или буферов из отдельного пула, выделенного устройству. В любом случае, драйвер устройства передает данные на уровень интерфейса в виде цепочки mbuf.
Некоторые драйверы получают кадры через канал DMA. В этом случае кадры записываются в закрепленную область памяти. После этого драйвер выделяет структуры mbuf и копирует в них данные. При получении кадров большого размера драйверы и адаптеры могут разместить кадры в кластерах. После этого драйвер передает кадр соответствующему сетевому протоколу (в данном примере - IP). Для этого вызывается функция разборки пакета, которая определяет тип пакета и помещает структуру mbuf, содержащую буфер данных, в очередь приема сетевого протокола. Если свободные структуры mbuf отсутствуют, или очередь верхнего уровня заполнена, поступающие кадры отбрасываются.