С помощью инструментов профилирования вы можете определить, какие части программы используются наиболее часто или обрабатываются дольше остальных. Эти инструменты обычно применяются в случае, если основное средство, такое как команда vmstat или iostat, указывает, что причина низкой производительности кроется в CPU.
Поиск "узких мест" в программе можно начинать только при условии, что в программе подключен полный набор функций и вы можете предоставить ей значения, близкие к реальным.
Для тестирования и отладки программ, производительность которых вы отслеживаете и пытаетесь повысить, воспользуйтесь командами измерения времени, рассмотренными в разделе Измерение времени использования CPU с помощью команды time. Вывод команды time содержит значения в минутах и секундах, как указано ниже:
реальное 0m26,72s польз. 0m26,53s системное 0m0,03s
Вывод команды timex содержит значения в секундах:
реальное 26,70 польз. 26,55 системное 0,02
Сравнение значений польз.+системное с реальным временем CPU позволит понять, что служит причиной низкой производительности приложения - CPU или средства ввода-вывода.
Примечание: Будьте особенно осторожны при выполнении этих операций в системе SMP (см. раздел Меры предосторожности при работе с time и timex).
Команду timex можно также запустить из программы SMIT, меню Инструменты анализа, раздел Планирование производительности и использования ресурсов. Опции -p и -s команды timex позволяют получать и вносить в отчет данные об учете ресурсов (-p) и вывод команды sar ( -s). Опция -o сообщает о числе считанных или записанных блоков.
Команда prof выдает информацию об использовании CPU для каждого внешнего идентификатора (функции) указанной программы. Это следующая информация:
Команда prof интерпретирует данные профилирования, собранные функцией monitor() для файла объекта (a.out по умолчанию), считывает таблицу идентификаторов из файла объекта и сопоставляет ее с файлом профайла (mon.out по умолчанию), созданным функцией monitor(). Отчет об использовании отправляется на терминал, но может быть перенаправлен и в файл.
Если вы хотите выполнить команду prof, откомпилируйте исходную программу на языке C, FORTRAN, PASCAL или COBOL с опцией -p. В этом случае в файл объекта будет вставлена специальная функция запуска профилирования, вызывающая функцию monitor() для отслеживания вызовов функций. Во время выполнения программы функция monitor() создает файл mon.out для отслеживания времени выполнения. Таким образом, файл mon.out создается только в случае явного вызова программ из главной программы или возврата ими управления главной программе. Кроме того, флаг -p указывает, что компилятор должен вставлять вызов функции mcount() в объектный код, создаваемый для каждой повторно компилируемой функции вашей программы. Во время выполнения программы, каждый раз, когда родительский процесс вызывает дочернюю функцию, последняя вызывает функцию mcount() для увеличения счетчика, соответствующего этой паре родитель-потомок, на единицу. Таким образом подсчитывается число обращений к функции.
Примечание: Команда prof не может применяться для профилирования оптимизированного кода.
По умолчанию показанный отчет упорядочивается по убыванию относительного времени CPU. Этому соответствует опция -t.
Опция -c упорядочивает отчет по убыванию числа вызовов, а опция -n - по идентификаторам в алфавитном порядке.
При применении опции -s создается итоговый файл mon.sum. Он полезен, когда в опции -m задано несколько файлов профайлов (опция -m задает файлы, содержащие данные монитора).
Опция -z означает включение в отчет всех идентификаторов, даже с нулевыми числом вызовов и долей затраченного времени.
Другие опции команды prof описаны в книге AIX 5L Version 5.1 Commands Reference.
В следующем примере показана первая часть вывода команды prof, примененной к модифицированной версии тестовой программы Whetstone (с двойной точностью).
# cc -o cwhet -p -lm cwhet.c # cwhet > cwhet.out # prof Имя % врем. Секунды Суммарн. #вызов. мс/вызов .main 32,6 17,63 17,63 1 17630, .__mcount 28,2 15,25 32,88 .mod8 16,3 8,82 41,70 8990000 0,0010 .mod9 9,9 5,38 47,08 6160000 0,0009 .cos 2,9 1,57 48,65 1920000 0,0008 .exp 2,4 1,32 49,97 930000 0,0014 .log 2,4 1,31 51,28 930000 0,0014 .mod3 1,9 1,01 52,29 140000 0,0072 .sin 1,2 0,63 52,92 640000 0,0010 .sqrt 1,1 0,59 53,51 .atan 1,1 0,57 54,08 640000 0,0009 .pout 0,0 0,00 54,08 10 0,0 .exit 0,0 0,00 54,08 1 0, .free 0,0 0,00 54,08 2 0, .free_y 0,0 0,00 54,08 2 0,
Из приведенного примера видно, что большое число вызовов приходится на функции mod8() и mod9(). Для начала выясните причину этого по исходному коду. Можно начать и с выяснения причин, по которым выполнение функции занимает столько времени.
Примечание: Если в программе, которую вы собираетесь отслеживать, применяется системный вызов fork(), то учтите, что родительский и дочерний процессы создают один и тот же файл (mon.out). Во избежание этого измените текущий каталог дочернего процесса.
Команда gprof создает профайл выполнения для программ на C, PASCAL, FORTRAN и COBOL. Статистические данные о вызываемых функциях включаются в профайл вызывающей программы. Команда gprof полезна при определении способов использования ресурсов CPU программой. С некоторыми оговорками ее можно считать расширением команды prof, которое предоставляет больше информации и лучше выделяет активные участки кода.
Исходный код должен быть откомпилирован с опцией -pg. Это действие связывает версии библиотечных функций, откомпилированных для профилирования, и считывает таблицу идентификаторов из именованного файла объекта (a.out по умолчанию), сопоставляя ее с файлом профайла схемы вызовов (gmon.out по умолчанию). Это означает, что компилятор вставляет вызов функции mcount() в объектный код, создаваемый для каждой повторно компилируемой функции вашей программы. Функция mcount() увеличивает счетчик на единицу каждый раз, когда родитель вызывает дочернюю функцию. Кроме того, функция monitor() оценивает время, затрачиваемое на выполнение каждой функции.
Команда gprof создает два полезных отчета:
Каждый раздел отчета начинается с пояснения содержимого столбцов вывода. Эти пояснения можно опустить, указав опцию -b.
Опция -s выдает итоги, опция -z - функции с нулевым показателем использования CPU.
При выполнении программы статистические данные заносятся в файл gmon.out. В эти данные входят:
Впоследствии команда gprof считывает файлы a.out и gmon.out и создает на их основе два отчета. Сначала генерируется профайл схемы вызовов, а затем простой профайл. Рекомендуется перенаправить вывод команды gprof в файл, поскольку, просмотрев сначала простой профайл, вы сможете уже получить ответы на многие вопросы.
В следующем примере показаны результаты профилирования для тестовой программы cwhet. Этот пример применялся и в разделе Команда prof:
# cc -o cwhet -pg -lm cwhet.c # cwhet > cwhet.out # gprof cwhet > cwhet.gprof
Профайл схемы вызовов является первой частью файла cwhet.gprof и выглядит примерно следующим образом:
шаг: каждое значение охватывает 4 байта Время: 62,85 с
вызовы/всего родитель.
индекс % врем. отдельн. потомки вызовы+отдел. имя index
вызовы/всего потомки
19,44 21,18 1/1 .__start [2]
[1] 64,6 19,44 21,18 1 .main [1]
8,89 0,00 8990000/8990000 .mod8 [4]
5,64 0,00 6160000/6160000 .mod9 [5]
1,58 0,00 930000/930000 .exp [6]
1,53 0,00 1920000/1920000 .cos [7]
1,37 0,00 930000/930000 .log [8]
1,02 0,00 140000/140000 .mod3 [10]
0,63 0,00 640000/640000 .atan [12]
0,52 0,00 640000/640000 .sin [14]
0,00 0,00 10/10 .pout [27]
-----------------------------------------------
<spontaneous>
[2] 64,6 0,00 40,62 .__start [2]
19,44 21,18 1/1 .main [1]
0,00 0,00 1/1 .exit [37]
-----------------------------------------------
Обычно отчет со схемой вызовов начинается с описания каждого столбца отчета, однако эта часть в данном примере опущена. Заголовки столбцов зависят от типа функции (текущая, предок текущей или потомок текущей). Текущая функция обозначена индексом в квадратных скобках в начале строки. Функции перечислены в порядке убывания затраченного времени CPU.
При чтении отчета обратите внимание на первый индекс [1] в крайнем левом столбце. Текущей является функция .main. Она была запущена функцией .__start (родительская функция указана над текущей) и, в свою очередь, запустила функции .mod8 и .mod9 (дочерние функции расположены под текущей). Все совокупное время функции .main распространяется и на функцию .__start. Значения в столбцах отдельн. и потомки потомков текущей функции увеличивают значение потомки для текущей функции. У текущей функции может быть несколько родителей. Время выполнения распределяется между родительскими функциями на основе количества обращений к ним.
Простой профайл является первой частью файла cwhet.gprof и выглядит примерно следующим образом:
шаг: каждое значение охватывает 4 байта Общее время: 62,85 с % суммарное отдельное отдельн. общее врем. в сек. в сек. вызовы мс/вызов мс/вызов имя 30,9 19,44 19,44 1 19440,00 40620,00 .main [1] 30,5 38,61 19,17 .__mcount [3] 14,1 47,50 8,89 8990000 0,00 0,00 .mod8 [4] 9,0 53,14 5,64 6160000 0,00 0,00 .mod9 [5] 2,5 54,72 1,58 930000 0,00 0,00 .exp [6] 2,4 56,25 1,53 1920000 0,00 0,00 .cos [7] 2,2 57,62 1,37 930000 0,00 0,00 .log [8] 2,0 58,88 1,26 .qincrement [9] 1,6 59,90 1,02 140000 0,01 0,01 .mod3 [10] 1,2 60,68 0,78 .__stack_pointer [11] 1,0 61,31 0,63 640000 0,00 0,00 .atan [12] 0,9 61,89 0,58 .qincrement1 [13] 0,8 62,41 0,52 640000 0,00 0,00 .sin [14] 0,7 62,85 0,44 .sqrt [15] 0,0 62,85 0,00 180 0,00 0,00 .fwrite [16] 0,0 62,85 0,00 180 0,00 0,00 .memchr [17] 0,0 62,85 0,00 90 0,00 0,00 .__flsbuf [18] 0,0 62,85 0,00 90 0,00 0,00 ._flsbuf [19]
Простой профайл значительно проще профайла схемы вызовов; он мало отличается от вывода команды prof. Основной интерес представляют столбцы отдельное в сек. и вызовы. Они отражают время CPU в секундах, затраченное на каждую функцию, и число вызовов каждой функции. В столбце отдельн. мс/вызов указано время CPU, затраченное самой функцией, а в столбце общее мс/вызов - время, затраченное самой функцией и всеми ее потомками.
Обычно оптимизацию проводят для функций, указанных в списке первыми, однако вы должны также обратить внимание на часто вызываемые функции. Иногда проще слегка усовершенствовать часто вызываемую функцию, чем вносить обширные изменения в код, вызываемый лишь однажды.
Последним генерируется индекс перекрестных ссылок; он выглядит следующим образом:
Индекс по имени функции [18] .__flsbuf [37] .exit [5] .mod9 [34] .__ioctl [6] .exp [43] .moncontrol [20] .__mcount [39] .expand_catname [44] .monitor [3] .__mcount [32] .free [22] .myecvt [23] .__nl_langinfo_std [33] .free_y [28] .nl_langinfo [11] .__stack_pointer [16] .fwrite [27] .pout [24] ._doprnt [40] .getenv [29] .printf [35] ._findbuf [41] .ioctl [9] .qincrement [19] ._flsbuf [42] .isatty [13] .qincrement1 [36] ._wrtchk [8] .log [45] .saved_category_nam [25] ._xflsbuf [1] .main [46] .setlocale [26] ._xwrite [17] .memchr [14] .sin [12] .atan [21] .mf2x2 [31] .splay [38] .catopen [10] .mod3 [15] .sqrt
[7] .cos [4] .mod8 [30] .write
Примечание: Если в программе, которую вы собираетесь отслеживать, применяется системный вызов fork(), то учтите, что родительский и дочерний процессы создают один и тот же файл (gmon.out). Во избежание этого измените текущий каталог дочернего процесса.
Стандартные средства анализа производительности UNIX обычно предоставляют недостаточно информации для полного описания всех факторов и функций, влияющих на производительность операционной системы. Подробные сведения об использовании CPU всеми процессами и функциями можно получить с помощью команды tprof. Более того, эта команда предоставляет информацию на уровне приложений, на уровне функций и даже на уровне исходных операторов, причем как глобально, так и подробно. Команда tprof также позволяет проанализировать расширения ядра, исполняемые программы без информации о компиляции и такие же библиотеки. Она выполняет сбор данных профилирования на уровне функций почти для всех исполняемых программ, для которых команда stripnm создает таблицу идентификаторов.
Поскольку выборка производится с частотой 100 раз в секунду, оценки для программ с малым временем выполнения могут быть недостаточно точными. Для получения более достоверной картины необходимо усреднить результаты по нескольким запускам. Команда tprof собирает информацию только о работе CPU; она не анализирует другие системные ресурсы, такие как оперативная и дисковая память.
Команда tprof использует системную функцию трассировки. Трассировщик не может запускаться несколькими пользователями одновременно. Как следствие, в каждый момент времени может выполняться только одна команда tprof.
Учтите, что команда tprof не может определить адрес функции, если прерывания отключены. По этой причине, все такты, произошедшие в то время, пока прерывания отключены, приписываются функциям unlock_enable().
Подробное описание команды tprof приведено в разделе Анализ использования CPU программами с помощью команды tprof. В оставшейся части данной главы обсуждается важность информации, предоставляемой этой командой, для настройки приложений.
Применение команды tprof не требует повторной компиляции, за исключением случаев профилирования на уровне исходных операторов. В этом случае откомпилируйте исходный код на языке C или FORTRAN с опцией -g.
Вывод команды tprof помещается в файл __программа.all (где программа - это имя профилируемой программы). В случае профилирования на уровне исходного кода создаются следующие дополнительные файлы, помещаемые в текущий рабочий каталог:
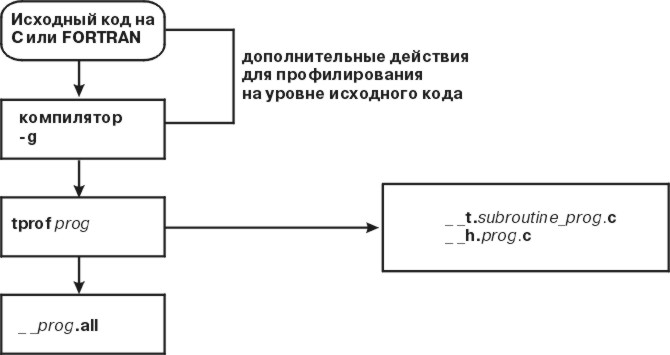
На следующем рисунке профилирование на уровне исходного кода представлено в виде блок-схемы:
Рис. 15-1. Профилирование на уровне исходного кода. Блок-схема начинается с блока, обозначенного Исходный код на C или FORTRAN. Путь, по которому перемещаются данные, ведет ко второму блоку, обозначенному Компилятор --g. Затем он достигает третьего блока, обозначенного Программа tprof. Здесь путь разветвляется. Возможны направления к последнему блоку, __программа.all, или к боковому блоку, __t.функция_программа.c и __h.программа.c. Первые два блока необязательны при профилировании на уровне исходного кода.
Команда tprof всегда создает по крайней мере один отчет - итоговый отчет с суффиксом .all. Первый раздел этого файла содержит оценки времени CPU, затраченного на каждый процесс во время выполнения программы или команды. В отчете указаны время CPU, а также время простоя и время ядра.
Второй раздел файла .all содержит результаты первого раздела, распределенные по процессам. В третьем разделе файла .all представлены результаты на уровне подпрограмм.
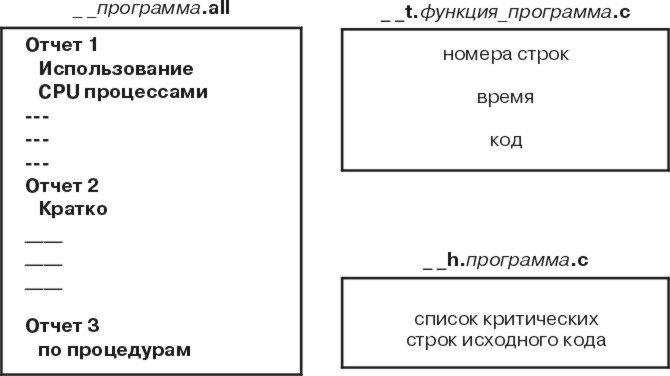
На следующем рисунке изображены наиболее важные из создаваемых файлов и их содержимое:
Рис. 15-2. Отчеты команды tprof. На этом рисунке изображены файлы, создаваемые командой tprof. Первый файл, __программа.all, содержит 3 отчета. В отчете 1 представлены показатели использования CPU по процессам. Отчет 2 является итоговым. В отчете 3 представлены результаты по функциям. Следующий файл - это __t.функция_программа.c. Он содержит номера строк, число тактов и код. Последним идет файл __h.программа.c. Этот файл содержит список наиболее активных строк исходного кода.
Пример вывода команды tprof приведен в разделе Пример применения tprof.