Если вы точно знаете, какие ресурсы ограничивают быстродействие программы, то можете сразу перейти к разделу, посвященному способам минимизации расхода соответствующих ресурсов. В противном случае следует исходить из того, что программа нуждается в оптимизации, и при этом будут использоваться все рассматриваемые в этой главе способы оптимизации. Если программа уже создана, ознакомьтесь с информацией из раздела Определение ресурса, служащего причиной снижения производительности.
Максимальная скорость обработки программы, если она действительно ограничена ресурсами процессора, зависит от следующих факторов:
Если процессор оказывается недостаточно мощным для обработки программы, так как эта программа выполняет огромное количество вычислений, то низкая производительность обусловлена неудачным выбором алгоритма. Однако вопросы, связанные с выбором алгоритма, выходят далеко за рамки этой книги. Поэтому в дальнейшем мы будем исходить из того, что выбран самый эффективный алгоритм.
Помимо выбора алгоритма, от программиста зависят только три фактора из числа перечисленных выше: исходный код, опции компилятора и, возможно, структуры данных. Последующие разделы посвящены способам повышения производительности конкретной программы в случае, если пользователь располагает ее исходным кодом. Если же исходного кода нет, попробуйте изменить конфигурацию или перераспределить ресурсы.
В начале книги (см. Глава 1. Основные сведения о производительности) уже упоминалось, что память процессора образует многоуровневую иерархию:
Каждый следующий уровень в этой иерархии обеспечивает меньшее быстродействие, чем предыдущий, зато больше по объему и дешевле. Следовательно, для достижения максимальной производительности на конкретном компьютере программист должен обеспечить максимальную эффективность работы с памятью на каждом уровне.
Эффективное использование памяти означает, что она должна быть полностью занята нужными командами и данными. К сожалению, память выделяется блоками фиксированной длины (например, целыми строками кэша или страницами реальной памяти), а программный код и структуры данных имеют различную длину, поэтому остаются неиспользуемые участки памяти. Если при разработке программ и структур данных не учитывалась иерархическая структура памяти, то память часто распределяется нерационально, что приводит к снижению производительности при работе в небольших или сильно загруженных системах.
Речь идет о том, что программист должен знать и соблюдать основные принципы повышения эффективности программы при работе с кэш-памятью или виртуальной памятью. С помощью средств создания пакетов можно увеличить производительность существующих программ без изменения исходного кода, а при написании новых программ следует стремиться к повышению эффективности работы с памятью.
При рассмотрении вопросов эффективного использования памяти с иерархической структурой следует уделить особое внимание таким понятиям, как компактность ссылок и рабочий набор.
У программы с высокой компактностью ссылок рабочий набор будет минимальным, поскольку используемые блоки памяти плотно заполнены фрагментами выполняемого кода и данными. В то же время у функционально эквивалентной программы с низким уровнем компактности ссылок рабочий набор будет больше, так как для размещения большого количества ссылок требуется много блоков памяти.
Поскольку загрузка каждого блока в память заданного уровня требует времени, для повышения эффективности программ в системе с иерархической структурой памяти следует разрабатывать и упаковывать программный код таким образом, чтобы рабочий набор был минимальным.
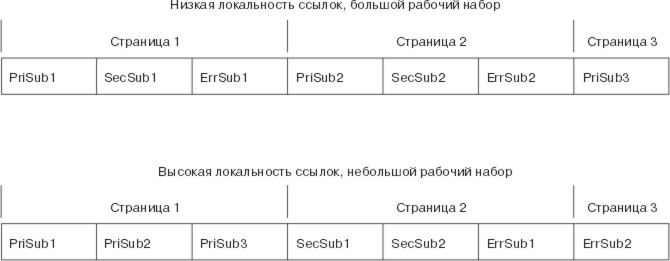
На следующем рисунке приведены примеры рационального и нерационального программирования на уровне процедур. В первом варианте порядок процедур в программе отражает лишь способ мышления автора. Первая функция PriSub1 содержит точку входа в программу. Она всегда вызывает вспомогательные функции PriSub2 и PriSub3. Дополнительные функции SecSub1 и SecSub2 предназначены для выполнения некоторых редко встречающихся задач. Функции обработки ошибок ErrSub1 и ErrSub2 вызываются только в исключительных случаях.
Рис. 4-1. Компактность ссылок. В верхней области рисунка продемонстрировано, что двоичная программа упакована с низким уровнем компактности ссылок. Инструкции функции PriSub1 расположены вначале двоичного исполняемого кода. За ними расположены инструкции функций SecSub1, ErrSub1, PriSub2, SecSub2, ErrSub2 и PriSub3. В данном случае инструкции функций PriSub1, SecSub1 и ErrSub1 расположены в первой странице памяти. Инструкции функций PriSub2, SecSub2 и ErrSub2 расположены во второй странице, а инструкции функции PriSub3 - в третьей странице памяти. Функции SecSub1 и SecSub2 используются редко, а функции ErrSub1 и ErrSub2 применяются лишь в исключительных ситуациях. Следовательно, эта программа упакована таким образом, что получился низкий уровень компактности ссылок. В результате программа занимает излишне много памяти. В нижней области рисунка показан альтернативный способ размещения программы в памяти. Функции PriSub1, PriSub2 и PriSub3 расположены в первой странице памяти. Функции PriSub3, SecSub1, SecSub2 и ErrSub1 расположены во второй странице памяти. Функция ErrSub2 занимает третью страницу памяти. Поскольку функция ErrSub2 практически никогда не используется, объем памяти, необходимый для работы программы, уменьшится на одну страницу.
Компактность ссылок первой версии программы низкая, так как в обычной ситуации для ее работы потребуется три страницы памяти. Дополнительные функции и функции обработки ошибок выделены в отдельные блоки, вследствие чего основной путь к программе распадается на три части, физически удаленные друг от друга.
В усовершенствованной версии программы все основные функции расположены в начале исполняемого кода. За ними следуют редко используемые функции. Необходимые (но крайне редко используемые) функции обработки ошибок помещены в конец программы. Теперь для выполнения большинства функций программы достаточно одной операции чтения с диска и одной страницы памяти вместо трех.
Помните, что компактность ссылок и рабочий набор определяются для конкретного момента времени. Если программа выполняется поэтапно, причем каждый этап занимает значительное время, и на каждом этапе вызываются разные функции, следует минимизировать рабочий набор для каждого этапа.
Как правило, размещение информации по регистрам, оптимизация регистров и заполнение конвейера осуществляются компилятором. Все, что требуется от программиста, - избегать конструкций, плохо поддающихся оптимизации. Например, если некоторая функция обрабатывается в одном из важнейших циклов программы, компилятор скорее всего попытается сделать эту функцию внутренней, чтобы не тратить время на загрузку. Если же функция содержится в другом исходном модуле (файле с расширением .c), компилятор не сможет сделать ее внутренней.
В зависимости от архитектуры и модели, процессор содержит один или несколько кэшей, которые предназначены для хранения следующих объектов:
Если при чтении из кэша произошел промах, загрузка полной строки кэша может растянуться на десять и более циклов процессора. Если произошел промах при операциях с TLB, на повторное вычисление таблицы преобразования виртуальных адресов в реальные может уйти несколько десятков циклов. Точные цифры зависят от реализации.
Даже если размеры фрагментов программы и блоков данных точно соответствуют размерам кэша, загрузка информации в кэш выполняется тем дольше, чем больше занято строк в кэше или записей TLB (т.е. чем ниже компактность ссылок). За исключением случая многократной обработки одних и тех же инструкций и данных, время на загрузку инструкций и данных составляет значительную часть общего времени выполнения программы, а увеличение объема загружаемых данных снижает быстродействие системы.
Оптимальный стиль программирования заключается в создании максимально компактной основной последовательности выполнения программы. Главная процедура и все подпрограммы, к которым она часто обращается, должны следовать друг за другом. Все маловероятные события, например, неожиданные ошибки, в ходе основной последовательности выполнения программы должны не обрабатываться, а только диагностироваться. Если такая ситуация действительно возникнет, она должна обрабатываться в отдельной процедуре. Все эти процедуры следует сгруппировать и поместить в конец модуля. Такая структура программы снизит вероятность того, что редко используемый код будет занимать место в кэше. Если модуль достаточно велик, то некоторые или все редко используемые процедуры будут расположены на странице, которая крайне редко загружается в память.
Это же правило относится и к структурам данных, хотя иногда приходится изменять код программы, чтобы компенсировать недостатки размещения данных компилятором.
Например, если напрямую запрограммировать операции с матрицами (в частности, умножение матриц), то у них будет очень низкий уровень компактности ссылок. В таких операциях почти всегда требуется перебрать все элементы матрицы по порядку. У каждого компилятора есть свои правила размещения матриц в памяти. Компилятор FORTRAN размещает матрицы по столбцам (то есть, сначала все элементы первого столбца, затем - второго и т.д.). В то же время компилятор C размещает матрицы по строкам. Для матриц небольшого размера все строки и столбцы умещаются в кэше одновременно, так что процессор и математический сопроцессор могут работать с полной скоростью. Однако по мере увеличения размера матрицы компактность ссылок для операций над строками и столбцами снижается, и, в конце концов, хранить данные в кэше становится невозможно. Происходит следующее: если строка матрицы длиннее строки кэша, то в ходе операции над строкой (например, умножения строки на столбец) уже помещенные в кэш элементы строки выбрасываются, а затем снова считываются, но уже с другой позиции. Таким образом, одни и те же данные помещаются в кэш несколько раз.
Общий рецепт для подобных случаев - разбить операцию на блоки так, чтобы над элементами, помещенными в кэш, можно было выполнить сразу несколько операций. Эта техника называется strip mining.
Перед специалистами по численным методам была поставлена задача - создать программы на основе алгоритмов работы с матрицами, использующие технику strip mining и другие способы оптимизации. В результате скорость умножения матриц повысилась в 30 раз. Эти оптимизированные процедуры входят в библиотеку основных функций линейной алгебры (BLAS), /usr/lib/libblas.a. Большое количество оптимизированных процедур содержится в лицензионной программе Engineering and Scientific Subroutine Library (ESSL).
Документация по функциям и интерфейсам из Библиотеки основных функций линейной алгебры приведена в книге AIX 5L Version 5.1 Technical Reference. Для работы с этой библиотекой необходимо установить среду времени выполнения FORTRAN. При выполнении операций с матрицами и векторами рекомендуется пользоваться готовыми процедурами из этой библиотеки, поскольку компактность ссылок для этих процедур значительно выше той, которой может достичь обычный пользователь.
Если структуры данных описываются программистом, в его распоряжении находятся и другие средства повышения эффективности. Общий принцип оптимизации данных - разместить часто используемые данные рядом друг с другом, насколько это возможно. Если структура данных содержит часто используемую управляющую информацию и подробную информацию, к которой обращаются сравнительно редко, то убедитесь, что управляющая информация расположена единым блоком, а не рассредоточена. Это увеличит вероятность того, что управляющая информация будет целиком загружена в кэш - как минимум, количество промахов будет сведено к минимуму.
Ниже приведены некоторые рекомендации для программиста, который хочет достичь максимальной скорости выполнения программы на конкретном компьютере:
Если у программиста нет возможности сравнить скорость выполнения оптимизированной и неоптимизированной программы, то он всегда должен использовать оптимизацию. Различие в скорости выполнения между оптимизированным и неоптимизированным кодом почти всегда оказывается столь велико, что в любом случае следует применять хотя бы базовый уровень оптимизации (опция -O в командах компиляторов). Единственным исключением являются ситуации, в которых нужна именно прямая компиляция - например, анализ производительности на уровне отдельных операторов с помощью средства tprof.
Эти методы способствуют повышению производительности для некоторых программ, однако для определения сочетания методов, дающего наибольший выигрыш в производительности для конкретной программы, может потребоваться огромное количество перекомпиляций и измерений.
Более подробная информация об эффективном использовании компиляторов приведена в книге Optimization and Tuning Guide for XL Fortran, XL C and XL C++.
Компиляторы поддерживают следующие уровни оптимизации:
В этом случае, в отличие от любых флагов типа -O, компилятор выполняет прямую компиляцию, не изменяя порядка следования инструкций, и не предпринимая никаких других попыток оптимизации.
Эти флаги эквивалентны и означают, что оптимизация должна выполняться практически без изменения порядка следования инструкций. Применяются только явно разрешенные (например, директивой #pragma) средства оптимизации. На этом уровне не применяются программный конвейер, преобразование циклов в линейный код и простое опережающее объединение. Кроме того, на этом уровне компилятору выделен ограниченный объем памяти.
Этот флаг разрешает компилятору применять все доступные средства оптимизации и снимает ограничения на объем памяти, выделенной компилятору.
Оптимизация на этом уровне может привести к неправильной работе программы, если в ней есть следующие особенности:
Этих побочных последствий оптимизации можно избежать, хотя и за счет некоторого снижения производительности, путем указания опции -qstrict вместе с опцией -O3.
Сочетание опций -qhot и -O3 разрешает опережающее объединение и, в некоторых случаях, развертку циклов.
Следовательно, в этой версии при компиляции больших или сложных процедур с опцией -O3 (возможно, вместе с опцией -qstrict или -qhot) достигается тот же или более высокий уровень производительности, чем в предыдущих версиях при компиляции с опцией -O.
В системах устанавливаются процессоры различных типов. Опции -qarch и -qtune позволяют оптимизировать программу с учетом специальных команд, поддерживаемых конкретным типом процессоров.
Ниже приведены некоторые рекомендации:
В данной операционной системе функции обработки строк можно встраивать в прикладную программу, а не считывать их из libc.a. При этом экономится время загрузки и возврата. Для встраивания функций обработки строк в программу перед вызовом функции в исходном коде нужно указать следующий оператор:
#include <string.h>
В большинстве случаев различия в производительности, связанные со стилем программирования на С или С++, неочевидны, а иногда их вообще можно определить только экспериментально. Ниже приведены некоторые рекомендации:
В большинстве случаев для обработки типов char и short требуется выполнить больше команд. Выполнение дополнительных команд занимает время, а кроме того, эти команды займут в исполняемом коде больше места, чем будет сэкономлено за счет применения более коротких чисел (если речь не идет о больших массивах данных).
Для загрузки данных типа signed char в регистр требуется выполнить на две команды больше, чем для данных типа unsigned char.
Для обращения к глобальным переменным требуется выполнить больше команд, чем для обращения к локальным переменным. Кроме того, если явно не указано иное, компилятор предполагает, что вызванная подпрограмма может изменять значения всех глобальных переменных. Таким образом, после вызова подпрограммы значения всех глобальных переменных загружаются в память повторно, что приводит к снижению производительности.
Использование локальной копии дает выигрыш в производительности, за исключением случая, когда обращение к глобальной переменной осуществляется только один раз.
#define situation_1 1 #define situation_2 2 #define situation_3 3 int situation_val; situation_val = situation_2; . . . if (situation_val == situation_1) . . .
выполняется намного быстрее, чем последовательность
char situation_val[20]; strcpy(situation_val,"situation_2"); . . . if ((strcmp(situation_val,"situation_1"))==0) . . .
Функции семейства mem*() (такие как memcpy()) выполняются быстрее соответствующих процедур семейства str*() (например, strcpy()). Это связано с тем, что в функциях семейства str*() каждый символ сравнивается с символом конца строки, в то время как в функциях mem*() этого не делается.
Для вызова компилятора C в операционной системе предусмотрено две команды: cc и xlc. Команда cc, изначально предназначенная для вызова системного компилятора C, запускает компилятор C в режиме langlevel=extended. В этом режиме можно скомпилировать старые программы на языке C, не совместимые со стандартом ANSI. При работе в этом режиме тратится больше процессорного времени.
Если компилируемая программа совместима со стандартом ANSI, то компилятор C лучше вызвать с помощью программы xlc.
Флаг -O3 неявно включает в себя опцию -qmaxmem. Эта опция снимает ограничения на объем памяти, доступный компилятору. Однако при этом возможны следующие побочные эффекты:
Для программистов, привыкших к работе в среде с ограниченным объемом адресуемой памяти, например, в DOS, объем сегмента виртуальной памяти размером 256 Мб кажется просто огромным. В результате программист вообще забывает об ограничениях на объем памяти. Но у этой медали есть и оборотная сторона. Объем виртуальной памяти действительно велик, но скорость доступа к ней непостоянна. Скорость доступа к виртуальной памяти снижается по мере ее заполнения, причем это отношение нелинейно. Пока общий объем виртуальной памяти, используемой всеми программами (т.е. общий объем всех рабочих наборов) не превышает объема свободной физической памяти, скорость доступа к виртуальной памяти почти не отличается от скорости доступа к физической. Когда же общий объем рабочих наборов всех выполняемых программ становится больше суммарного объема доступных страниц памяти, скорость доступа начинает быстро снижаться (при выключенном механизме управления нагрузкой VMM) и в конце концов уменьшается на два порядка. Такое состояние называется перегрузкой памяти. Почти все время система занимается перемещением страниц, и ни одно задание не может завершиться, поскольку каждый процесс пытается отвоевать у остальных объем памяти, необходимый для размещения соответствующего рабочего набора. Если включен механизм управления нагрузкой на память VMM, то он может предотвратить загрузку, но за счет значительного увеличения времени ответа.
Снижение производительности вследствие неэффективного использования памяти намного более ощутимо, чем снижение производительности вследствие неэффективного использования кэша, поскольку скорости памяти и диска отличаются намного больше, чем скорости кэша и памяти. В то время как обработка промаха в кэше занимает несколько десятков циклов процессора, обработка страничной ошибки занимает не менее 10 миллисекунд, что эквивалентно по крайней мере 400 000 циклам процессора.
Хотя средство управления нагрузкой на память VMM не позволяет довести перегрузку памяти до тупиковой ситуации, дополнительные страничные ошибки приводят к увеличению времени ответа и снижению производительности (см. Настройка средства управления нагрузкой на память VMM с помощью команды schedtune).
Общая рекомендация по минимизации рабочего набора программы заключается в том, чтобы выделить небольшую область для часто используемых фрагментов кода, отделив их от редко используемых фрагментов. Ниже приведены некоторые рекомендации:
Для минимизации рабочего набора данных попытайтесь собрать все часто обрабатываемые данные вместе и удалить ненужные ссылки на страницы виртуальной памяти. Более конкретные рекомендации приведены ниже:
Для предотвращения зацикливания и тайм-аутов небольшая часть системы должна располагаться в закрепленной области оперативной памяти. Для этих фрагментов кода и данных понятие рабочего набора лишено смысла, поскольку вся информация постоянно находится в памяти, вне зависимости от того, используется она или нет. Программы, в которых применяется резидентный код или данные (например, пользовательские драйверы устройств), нуждаются в особо тщательной разработке (а готовые программы - в тщательном анализе), чтобы эти программы не занимали слишком много памяти. Ниже приведено несколько примеров: