Обычно программист представляет себе выполнение программы как последовательную обработку инструкций, составляющих определенную функцию. Значительная доля усилий разработчиков аппаратного и программного обеспечения тратится на то, чтобы программистам не нужно было отказываться от этой идеализированной картины при работе в современных многопроцессорных и многозадачных системах с большой памятью и высоким быстродействием. Однако если программист не откажется от подобной иллюзии, то создаваемые им программы будут выполняться медленно и с большими затратами ресурсов системы.
Для того чтобы получить правильное представление о параметрах рабочей схемы, необходимо использовать динамическую, а не статическую модель выполнения программы. Она показана на следующем рисунке.
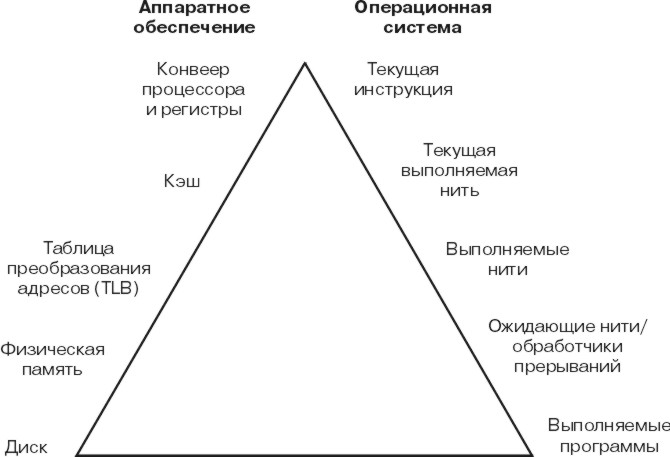
Рис. 1-1. Иерархия выполнения программы. Схема представляет собой треугольник. С левой стороны перечислены компоненты аппаратного обеспечения, соответствующие компонентам операционной системы, перечисленным с правой стороны. Программа переходит с нижнего уровня, на котором она представляет собой набор данных, хранящихся на диске, на верхний уровень, на котором инструкции программы выполняются процессором. Например, если перечислить все уровни, начиная с нижнего, то на диске хранятся исполняемые программы, в оперативной памяти хранятся ожидающие нити операционной системы и обработчики прерываний, в буфере таблицы преобразования адресов хранятся нити, готовые к выполнению, в кэше хранятся нити, переданные на выполнение, а в регистрах и конвейере процессора находятся выполняемые в данный момент инструкции.
В процессе выполнения программа должна пройти все этапы аппаратной и программной иерархии, более или менее параллельно. Каждый элемент в аппаратной иерархии имеет большую ценность, чем элемент, расположенный ниже него. Программа конкурирует с другими программами за каждый ресурс, а переход с одного уровня на другой занимает некоторое время. Для того чтобы понять, в чем заключается процесс выполнения программы, нужно иметь представление о каждом из уровней иерархии.
Обычно время, необходимое для перехода с одного аппаратного уровня на другой, зависит от времени ожидания на нижнем уровне. Под временем ожидания понимается время, проходящее с момента отправки запроса до получения первых данных.
При выполнении программы больше всего времени затрачивается на считывание исходного кода и данных программы с жесткого диска (если не учитывать время, затрачиваемое на ожидание ввода пользователя). Это время тратиться на выполнение следующих действий:
Обращения к диску могут быть вызваны не только явными запросами прикладной программы. Иногда настройка системы может привести к выполнению ненужных операций дискового ввода-вывода.
Обращения к оперативной памяти (RAM) обрабатываются намного быстрее, чем обращения к диску, однако оперативная память значительно дороже дисковой. Операционные системы стараются хранить в оперативной памяти только те инструкции и данные, которые используются в текущий момент, выгружая ненужную информацию на диск (или вообще не загружая ее в память).
Скорость работы оперативной памяти не обязательно сравнима со скоростью процессора. Задержка между обращением аппаратного обеспечения к оперативной памяти и получением данных или инструкций процессором может составлять порядка десяти тактов процессора.
При обращении к странице виртуальной памяти, выгруженной на диск (или еще не загруженной в оперативную память), возникает страничная ошибка, и выполнение программы прерывается до тех пор, пока страница не будет считана с диска.
Одним из способов освобождения программ от физических ограничений системы является использование виртуальной памяти. Программист разрабатывает и кодирует приложение так, как если бы объем памяти был очень большим, а система, в свою очередь, отвечает за преобразование виртуальных адресов инструкций и данных в адреса физической памяти. Для того чтобы уменьшить время, затрачиваемое на преобразование адресов, физические адреса тех страниц виртуальной памяти, к которым обращались в последнее время, хранятся в кэше, который называется таблицей преобразования адресов (TLB).
До тех пор пока программа обращается к небольшому числу страниц виртуальной памяти, полное преобразование виртуальных адресов не производится. Если программа обращается к странице, для которой в таблице TLB отсутствует запись (промах TLB), то на преобразование адреса затрачивается порядка десяти тактов процессора (время обработки промаха TLB).
Для минимизации задержек, связанных с обращением к оперативной памяти, в системе предусмотрен кэш для команд и данных. Если необходимые команды или данные находятся в кэше (попадание), то они будут переданы процессору уже на следующем такте (другими словами, задержки не будет). В противном случае некоторое время будет затрачено на обращение к оперативной памяти (промах кэша).
В некоторых системах кэши расположены на двух или трех уровнях. Обычно они называются кэшами L1, L2 и L3. Если необходимые данные не будут найдены в кэше L1, то система попытается найти их в кэше L2. В случае промаха в кэше L2 система переходит на уровень L3 (если он есть) или к оперативной памяти.
Размер и структура кэша зависит от модели системы, однако принцип его работы одинаковый.
При соблюдении некоторых условий конвейерная архитектура дает возможность одновременно обрабатывать несколько инструкций. Большой набор регистров общего назначения и регистров для чисел с плавающей точкой позволяет хранить значительную часть данных программы в регистрах, без необходимости постоянного обращения к памяти.
При оптимизации программы компилятор старается задействовать максимальное число регистров. При компиляции программ всегда следует включать функцию оптимизации, независимо от размера программы. Более подробная информация об эффективном использовании компиляторов приведена в книге Optimization and Tuning Guide for XL Fortran, XL C and XL C++.
Во время выполнения программа проходит ряд уровней в программной иерархии.
Когда пользователь запускает программу, операционная система выполняет ряд действий для преобразования кода и данных программы, хранящихся на диске, в работающую программу. Сначала выполняется поиск требуемой копии программы в соответствии с текущей переменной среды PATH, установленной для пользователя. Затем загрузчик программы (не путайте с редактором связей - командой ld) преобразует внешние ссылки программы на общие библиотеки.
В ответ на получение запроса пользователя операционная система создает процесс, представляющий собой набор ресурсов, необходимых для выполнения программы (он включает в себя частный сегмент виртуальной памяти).
В AIX версии 4 операционная система дополнительно создает нить процесса. Нить определяет текущее состояние выполнения отдельного экземпляра программы. В AIX версии 4 время процессора и другие ресурсы выделяются отдельным нитям, а не всему процессу. Прикладная программа может создавать несколько нитей внутри одного процесса. Такие нити совместно используют ресурсы процесса, в котором они запущены.
Наконец, система выполняет переход на точку входа программы. Если страница, содержащая точку входа, еще не загружена в память (это может произойти в случае, если программа недавно компилировалась, запускалась или копировалась), происходит страничная ошибка, и страница загружается в память с диска.
Для оповещения операционной системы о каком-либо внешнем событии применяется механизм прерываний, который позволяет приостановить выполнение текущей нити и передать управление обработчику прерываний. Перед запуском обработчика прерываний сохраняется информация о состоянии аппаратных компонентов, чтобы после обработки прерывания система могла восстановить среду выполнения нити. На работе обработчика прерываний сказываются те же задержки, связанные с перемещением по аппаратной иерархии, что и на работе обычных программ (исключение составляют страничные ошибки). Если обработчик прерываний вызывался достаточно давно (и программа не является крайне экономной по отношению к ресурсам), то маловероятно, что его код или дата сохранятся в TLB или кэш-памяти.
Когда прерванная нить снова передается на выполнение, ее контекст (в частности, содержимое регистров) восстанавливается, поэтому она может продолжить свою работу. При этом содержание TLB и кэш-памяти формируется на основе последующих запросов программы. Таким образом, и в обработчике прерываний, и в прерванной программе будут возникать серьезные задержки, связанные с промахами при обращении к кэшу и TLB.
Если запрос программы нельзя обработать немедленно, (например, операцию ввода-вывода нельзя выполнить из-за страничной ошибки), то до окончания обработки запроса нить переходит в состояние ожидания. Как правило, это приводит к дополнительным задержкам при работе с TLB и кэшем, не считая самого времени обработки запроса.
Нить, ожидающая передачи на выполнение, фактически простаивает. Кроме того, для выполнения текущих нитей в кэше могут быть удалены данные нити, ожидающей передачи на выполнение, а из оперативной памяти могут быть выгружены ее страницы данных. Следовательно, когда нить будет передана на выполнение, возникнут дополнительные задержки при обращении к кэшу и оперативной памяти.
Планировщик выбирает для выполнения нить, которая имеет максимальные потребности по использованию ресурсов процессора. Алгоритм выбора нитей для их передачи на выполнение описан в разделе Планировщик CPU - Обзор. Когда нить передается на выполнение, восстанавливается то состояние процессора, которое было в тот момент, когда ее выполнение было в последний раз прервано.
Большинство машинных инструкций выполняются за один такт процессора, если при обращении к TLB или кэшу не возникнет промах. Однако если часто выполняется переход к различным частям программы, а данные считываются из различных областей памяти, то при обращении к TLB и кэшу возникает большое число промахов. В результате число тактов процессора, затрачиваемых на выполнение одной инструкции (CPI), может быть намного больше единицы. В этом случае говорят, что в программе ссылки расположены не компактно. Даже если программа содержит небольшое число инструкций, на их выполнение может быть затрачено довольно много тактов процессора. Это одна из причин, по которой нельзя оценить время выполнения программы, подсчитав число инструкций. Как правило, чем короче программа, тем быстрее она выполняется, однако размер программы не прямо пропорционален времени ее выполнения.
Компилятор оптимизирует код программы таким образом, чтобы минимизировать число тактов процессора, необходимых на выполнение программы. Для того чтобы добиться максимальной производительности программы, нужно предоставить компилятору полную информацию, необходимую для эффективной оптимизации, а не строить предположения о том, какой способ оптимизации будет выбран компилятором (за дополнительной информацией обратитесь к разделу Повышение эффективности работы препроцессоров и компиляторов). Настоящим показателем производительности может служить только скорость обработки конкретной рабочей схемы.