Понятие кодового набора тесно связано с понятием набора символов. Набор символов - это совокупность определенных знаков, применяемых в одном или нескольких языках. Он не зависит от способа кодирования символов. Выбор кодового набора для данного набора символов зависит от того, какие требования предъявляются к скорости обработки данных. Один и тот же набор символов можно закодировать различными способами. Например, набор символов ASCII - это совокупность всех символов английского языка. Набор символов JIS (японский промышленный стандарт) - это совокупность всех символов японского языка. Оба этих набора можно кодировать с помощью различных кодовых наборов.
В соответствии со стандартом ISO2022, набор кодированных символов - это совокупность правил, которые определяют набор символов и взаимно-однозначное соответствие между символами и битовыми шаблонами. Совокупность битовых шаблонов называют кодовым набором.
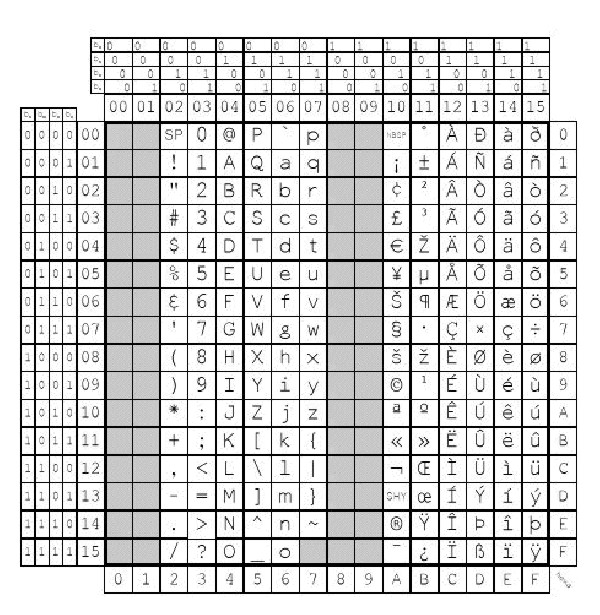
Кодовая страница - это кодовый набор, представленный в виде квадратной матрицы размером 16х16. Каждая ячейка матрицы кодирует один символ.
Поддерживаются следующие кодовые наборы:
Дополнительные сведения о кодовых наборах вы найдете в следующих разделах:
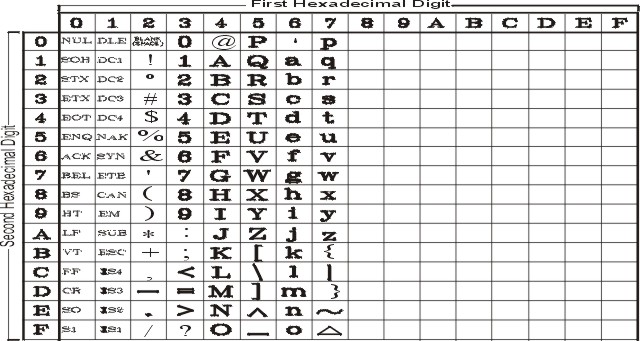
Ниже описаны 7-разрядные символы ASCII.
В следующей таблице приведены
символы ASCII, лежащие в диапазоне уникальных кодовых знаков. Их коды
находятся в диапазоне от 0x00 до 0x3F.
| Символы ASCII с уникальными кодами | |||||
| Название символа | Шестн. код | Вид | Название символа | Шестн. код | Вид |
| nul | 00 |
| пробел | 20 | blank |
| soh | 01 |
| восклицательный знак | 21 | ! |
| stx | 02 |
| кавычка | 22 | " |
| etx | 03 |
| символ номера | 23 | # |
| eot | 04 |
| обозначение доллара | 24 | $ |
| enq | 05 |
| знак процентов | 25 | % |
| ack | 06 |
| амперсанд | 26 | & |
| alert | 07 |
| апостроф | 27 | ' |
| забой | 08 |
| открывающая круглая скобка | 28 | ( |
| tab | 09 |
| закрывающая круглая скобка | 29 | ) |
| newline | 0A |
| звездочка | 2A | * |
| вертикальная табуляция | 0B |
| плюс | 2B | + |
| form-feed | 0C |
| запятая | 2C | , |
| carriage-return | 0D |
| дефис | 2D | - |
| so | 0E |
| точка | 2E | . |
| si | 0F |
| косая черта | 2F | / |
| dle | 10 |
| цифра 0 | 30 | 0 |
| dc1 | 11 |
| цифра 1 | 31 | 1 |
| dc2 | 12 |
| цифра 2 | 32 | 2 |
| dc3 | 13 |
| цифра 3 | 33 | 3 |
| dc4 | 14 |
| цифра 4 | 34 | 4 |
| nak | 15 |
| цифра 5 | 35 | 5 |
| syn | 16 |
| цифра 6 | 36 | 6 |
| etb | 17 |
| цифра 7 | 37 | 7 |
| can | 18 |
| цифра 8 | 38 | 8 |
| em | 19 |
| цифра 9 | 39 | 9 |
| sub | 1A |
| двоеточие | 3A | : |
| esc | 1B |
| точка с запятой | 3B | ; |
| is1 | 1C |
| знак "меньше" | 3C | < |
| is2 | 1D |
| знак равенства | 3D | = |
| is3 | 1E |
| знак "больше" | 3E | > |
| is4 | 1F |
| вопросительный знак | 3F | ? |
В этой таблице приведены 7-разрядные символы ASCII с неуникальными
кодами. Коды лежат в пределах от 0x40 до 0x7F.
| Прочие символы ASCII | |||||
| Название символа | Шестн. код | Вид | Название символа | Шестн. код | Вид |
| коммерческое "at" | 40 | @ | обратный апостроф | 60 | ` |
| A | 41 | A | a | 61 | a |
| B | 42 | B | b | 62 | b |
| C | 43 | C | c | 63 | c |
| D | 44 | D | d | 64 | d |
| E | 45 | E | e | 65 | e |
| F | 46 | F | f | 66 | f |
| G | 47 | G | g | 67 | g |
| H | 48 | H | h | 68 | h |
| I | 49 | I | i | 69 | i |
| J | 4A | J | j | 6A | j |
| K | 4B | K | k | 6B | k |
| L | 4C | L | l | 6C | l |
| M | 4D | M | m | 6D | m |
| N | 4E | N | n | 6E | n |
| O | 4F | O | o | 6F | o |
| P | 50 | P | p | 70 | p |
| Q | 51 | Q | q | 71 | q |
| R | 52 | R | r | 72 | r |
| S | 53 | S | s | 73 | s |
| T | 54 | T | t | 74 | t |
| U | 55 | U | u | 75 | u |
| V | 56 | V | v | 76 | v |
| W | 57 | W | w | 77 | w |
| X | 58 | X | x | 78 | x |
| Y | 59 | Y | y | 79 | y |
| Z | 5A | Z | z | 7A | z |
| открывающая квадратная скобка | 5B | [ | открывающая фигурная скобка | 7B | { |
| обратная косая черта | 5C | \ | вертикальная черта | 7C | | |
| закрывающая квадратная скобка | 5D | ] | закрывающая фигурная скобка | 7D | } |
| циркумфлекс | 5E | ^ | тильда | 7E | ~ |
| символ подчеркивания | 5F | _ | del | 7F | |
До появления версии 3.2 операционная система AIX поддерживала только два кодовых набора: IBM-850 и IBM-932. В версии 3.2 поддержка кодовых наборов была расширена: были добавлены наборы на основе кодовых наборов ISO (Международной организации по стандартизации) и промышленных стандартов. Пользователям рекомендуется работать с этими новыми кодовыми наборами. Конечная цель фирмы IBM - предоставить пользователям кодовые наборы промышленных стандартов, позволяющие обрабатывать данные всех необходимых типов.
В последующих версиях AIX кодовый набор IBM-850 поддерживаться не будет. В связи с этим пользователям, работающим с локалями на основе IBM-850, настоятельно рекомендуется перейти к соответствующей локали на основе промышленного стандарта ISO8859-1. Например: от французской локали IBM-850 (Fr_FR) следует перейти к французской локали ISO8859-1 (fr_FR).
Каждая локаль системы определяет применяемый кодовый набор и способ обработки символов из этого набора. Поскольку в системе можно установить сразу несколько локалей, разные пользователи могут работать с разными кодовыми наборами. Однако несмотря на то, что в системе можно настроить локали с различными кодовыми наборами, все системные утилиты работают с одним кодовым набором.
Большинство команд не зависят от конкретного кодового набора, применяемого локалью. Вся информация о кодовых наборах хранится в библиотеке функций, не зависящих от кодового набора (библиотеке NLS), и эти функции передают необходимые данные функциям, зависящим от кодового набора.
Поскольку многие программы основаны на применении кодов ASCII, все кодовые наборы содержат 7-разрядные ASCII-символы в качестве подмножества. Так как набор 7-разрядных символов ASCII совпадает у всех поддерживаемых кодовых наборов, его иногда называют переносимым набором символов.
Кодовый набор 7-разрядных ASCII-символов описан в стандарте ISO646 и содержит управляющие символы, знаки препинания, цифры (0-9) и строчные и прописные буквы английского алфавита.
Каждый кодовый набор подразделяется на две основные области:
| Левая группа символов (GL) | Колонки 0-7 |
| Правая группа символов (GR) | Колонки 8-F |
Первые две колонки в каждом кодовом наборе зарезервированы Международной организацией по стандартизации (ISO) для управляющих символов. C0 и C1 - это обозначения управляющих символов соответственно левой и правой групп символов.
Примечание: В кодовых наборах IBM PC область управляющих символов C1 применяется для кодирования графических символов.
Остальные 6 колонок кодируют графические символы. Графическими называют символы, которые выводятся на экран или на принтер, а управляющими - символы, которые обозначают какую-либо специальную функцию и служат для управления процессом вывода.
Управляющие символы основаны на стандарте ISO. Каждый из них
запускает, изменяет или завершает какую-либо управляющую операцию.
Управляющий символ не является графическим, но в некоторых случаях может быть
представлен и графически. Управляющие символы из следующей таблицы
входят во все поддерживаемые кодовые наборы, и их кодовые знаки действительны
в каждом из этих наборов.
Табл. 16-1. Таблица кодовых знаков управляющих символов
| NUL | 00 | Пусто |
| SOH | 01 | Начало заголовка |
| STX | 02 | Начало текста |
| ETX | 03 | Конец текста |
| EOT | 04 | Конец связи |
| ENQ | 05 | Запрос |
| ACK | 06 | Подтверждение |
| BEL | 07 | Звонок |
| BS | 08 | Забой |
| HT | 09 | Горизонтальная табуляция |
| LF | 0A | Новая строка |
| VT | 0B | Вертикальная табуляция |
| FF | 0C | Новая страница |
| CR | 0D | Возврат каретки |
| SO | 0E | Открывающий символ |
| SI | 0F | Закрывающий символ |
| DLE | 10 | Переход при передаче данных |
| DC1 | 11 | Управление устройством, 1 |
| DC2 | 12 | Управление устройством, 2 |
| DC3 | 13 | Управление устройством, 3 |
| DC4 | 14 | Управление устройством, 4 |
| NAK | 15 | Нет подтверждения |
| SYN | 16 | Синхронизация |
| ETB | 17 | Конец блока передачи |
| CAN | 18 | Отмена |
| EM | 1 | Конец носителя |
| SUB | 1A | Символ замены |
| ESC | 1B | Управляющий символ |
| IS4 | 1C | Разделитель 4 |
| IS3 | 1D | Разделитель 3 |
| IS2 | 1E | Разделитель 2 |
| IS1 | 1F | Разделитель 1 |
Каждый кодовый набор можно разделить на несколько наборов символов так, чтобы каждому символу соответствовало уникальное кодовое значение. Стандарт ISO резервирует шесть колонок таблицы для кодирования графических символов и запрещает кодировать графические символы в колонках, предназначенных для управляющих символов.
Работа с AIX в различных языковых средах возможна благодаря тому, что все кодовые наборы допускают разделение на любое количество наборов символов.
Кодовые наборы, в которых каждый символ кодируется одним байтом (8 битами), могут поддерживать языки, основанные на алфавите (европейские, иврит и т.п.). Такие кодовые наборы называются наборами однобайтовых символов. Однако они не могут содержать более 191 символа (не считая управляющих).
Для языков, в которых применяется более 191 символа, требуется сочетание однобайтовых (8 бит) и многобайтовых (более 8 бит) символов. В этом случае можно кодировать символ с помощью любого количества битов.
Определения Международной организации по стандартизации (ISO) служат основой для следующих кодовых наборов:
В таблице "Кодовый набор ISO646-IRV" показан кодовый набор, который применяется для обработки данных, основанной на 7-разрядном кодировании. Связанный с ним набор символов является расширением набора ASCII-символов.
ISO8859 - это семейство кодовых наборов однобайтовых символов, которые основаны на методах расширенного кодирования ISO, ANSI (Американского национального института стандартов) и ECMA (Европейской ассоциации производителей вычислительной техники) и совместимы с ними. ISO8859 определяет семейство кодовых наборов, каждый из которых содержит собственный уникальный набор символов, а также набор 7-разрядных символов ASCII в качестве подмножества.
Кодовый набор ASCII упорядочен в соответствии с английским алфавитом. В отличие от этого, порядок символов в правой области (GR) не связан с каким-либо алфавитом. Порядок, соответствующий конкретному языку, определяется локалью.
Каждый кодовый набор включает набор символов ASCII и собственный уникальный
набор символов. Таблица кодирования ISO8859 иллюстрирует общую схему
кодирования ISO8859.
| Кодировка | Кодовый знак | Описание | Количество |
| 000xxxxx | 00-1F | Управляющие символы | 32 |
| 00100000 | 20 | Пробел | 1 |
| 0xxxxxxx | 21-7E | 7-разрядные символы | 94 |
| 01111111 | 7F | Delete | 1 |
| 100xxxxx | 80-9F | Управляющие символы | 32 |
| 10100000 | A0 | Неразрывный пробел | 1 |
| 1xxxxxxx | A1-F | 8-разрядные символы | 96 |
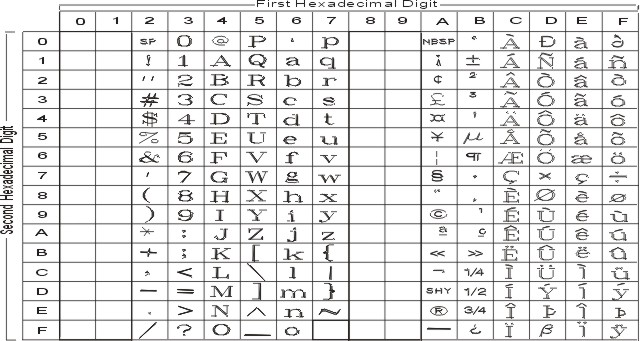
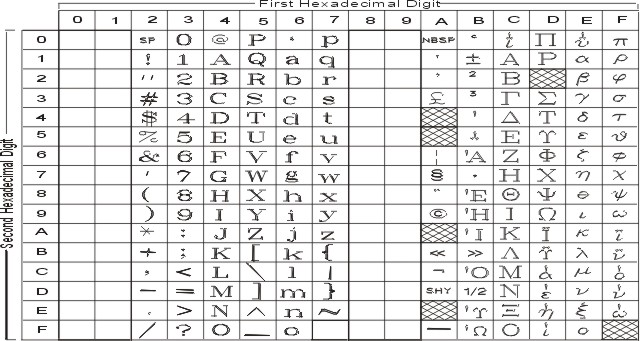
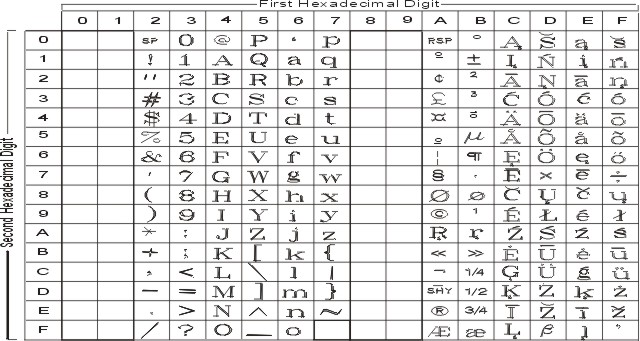
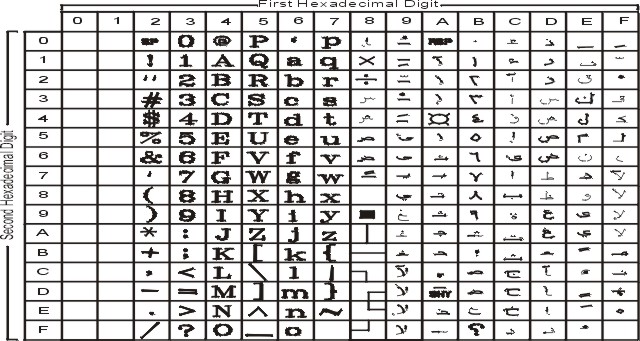
На рисунке показаны все символы и раскладка кодового набора ISO8859-1. Текстовое представление этого кодового набора приведено в разделе ISO8859-1.
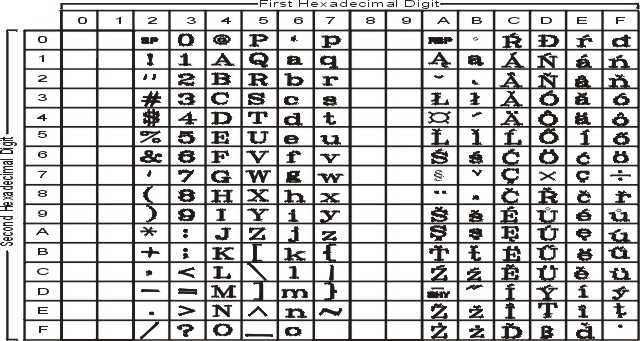
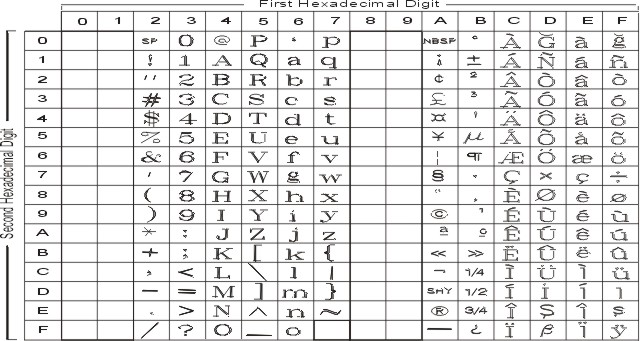
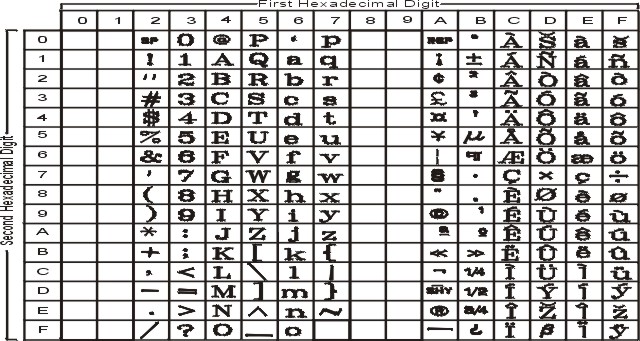
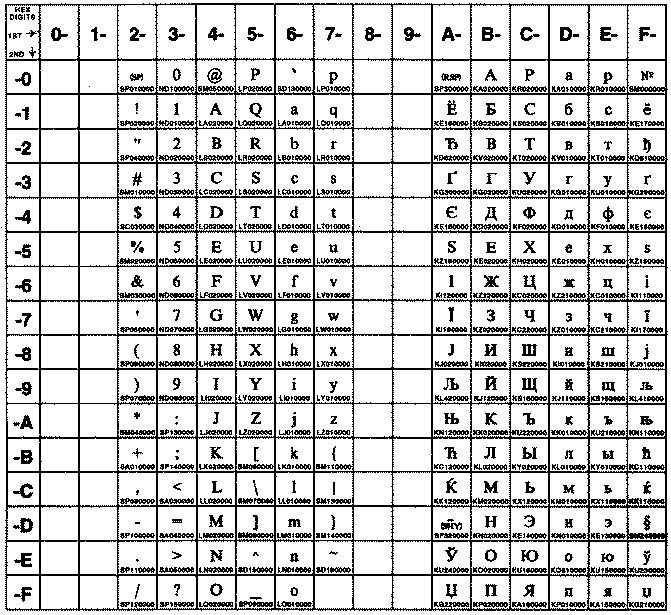
На рисунке показаны все символы и раскладка кодового набора ISO8859-2. Текстовое представление этого кодового набора приведено в разделе ISO8859-2.
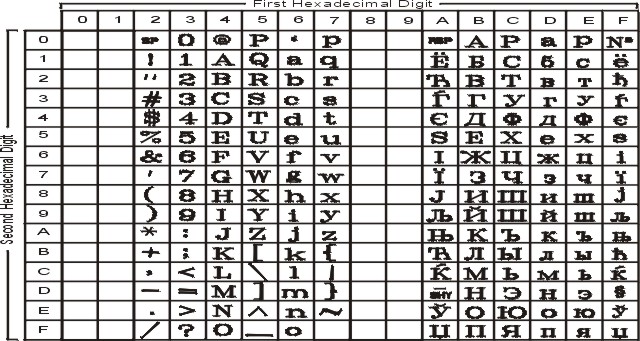
На рисунке показаны все символы и раскладка кодового набора ISO8859-5. Текстовое представление этого кодового набора приведено в разделе ISO8859-5.
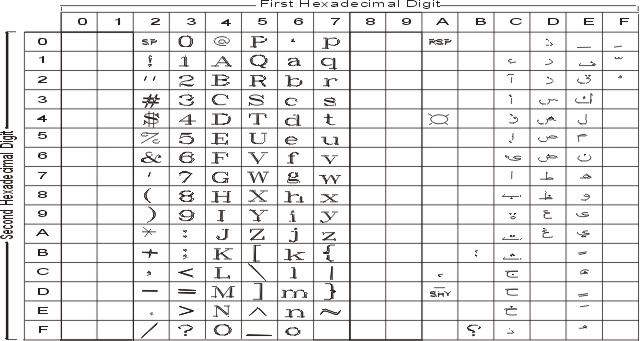
На рисунке показаны все символы и раскладка кодового набора ISO8859-6. Текстовое представление этого кодового набора приведено в разделе ISO8859-6.
На рисунке показаны все символы и раскладка кодового набора ISO8859-7. Этот кодовый набор состоит из символов ASCII и собственного уникального набора символов. Текстовое представление этого кодового набора приведено в разделе ISO8859-7.
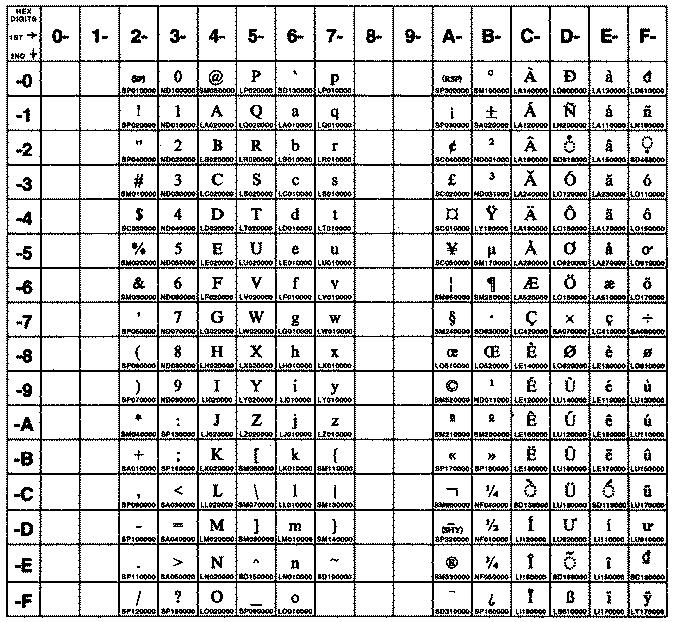
На рисунке показаны все символы и раскладка кодового набора ISO8859-8. Текстовое представление этого кодового набора приведено в разделе ISO8859-8.
На рисунке показаны все символы и раскладка кодового набора ISO8859-9. Этот кодовый набор состоит из символов ASCII и собственного уникального набора символов. Текстовое представление этого кодового набора приведено в разделе ISO8859-9.
На рисунке показаны все символы и раскладка кодового набора ISO8859-15. Текстовое представление этого кодового набора приведено в разделе ISO8859-15.
Схема EUC определяет набор правил кодирования, которые могут поддерживать
от 1 до 4 наборов символов. Эти правила основаны на определении ISO2022
для кодирования 7- и 8-разрядных данных. Для идентификации некоторых
наборов символов в схеме кодирования EUC применяются управляющие
символы. В следующей таблице проиллюстрирован общий принцип кодирования
EUC.
Табл. 16-3. Таблица кодирования EUC
| CS0 | 0xxxxxxx |
| CS1 | 1xxxxxxx
1xxxxxxx 1xxxxxxxx 1xxxxxxx 1xxxxxxxx 1xxxxxxx ... |
| CS2 | 10001110 1xxxxxxx
10001110 1xxxxxxx 1xxxxxxxx 10001110 1xxxxxxx 1xxxxxxxx 1xxxxxxxx ... |
| CS3 | 10001111 1xxxxxxx
10001111 1xxxxxxx 1xxxxxxxx 10001111 1xxxxxxx 1xxxxxxxx 1xxxxxxxx ... |
Термин EUC обозначает рассматриваемые общие правила кодирования. Кодовый набор, основанный на EUC, подчиняется его правилам кодирования, но, кроме того, определяет конкретные наборы символов, соответствующие конкретным локалям. Например, набор IBM-eucJP для Японии кодирует символы японского промышленного стандарта в соответствии с правилами EUC.
Первый набор (CS0) всегда включает набор символов ISO646. Все остальные наборы могут использовать любое количество байт для кодирования символа, но их MSB (самый старший разряд) должен быть равен 1. Кроме того, все символы набора должны:
Перед каждым символом из третьего набора (CS2) всегда стоит управляющий символ SS2 (single shift 2, 0x8e). В кодовых наборах EUC этот символ (SS2) применяется исключительно для обозначения третьего набора.
Перед каждым символом из четвертого набора (CS3) всегда стоит управляющий символ SS3 (single shift 3, 0x8f). В кодовых наборах EUC этот символ (SS3) применяется исключительно для идентификации четвертого набора.
EUC для японского языка - это кодовый набор, состоящий из однобайтовых и многобайтовых символов. Он основан на стандарте ISO2022, Японском промышленном стандарте (JIS) и определениях EUC.
Кодовый набор IBM-eucJP состоит из следующих наборов символов:
| JISCII | Левая группа символов JISX0201 |
| JISX0201.1976 | Правая группа символов Катакана/Хирагана |
| JISX0208.1983 | Наборы символов Канжи уровней 1 и 2 |
| IBM-udcJP | Пользовательские символы |
Кроме того, IBM-eucJP может поддерживать следующие наборы символов:
| JISX0212.1990 | Канжи - дополнительный |
Кодовый набор IBM-eucJP кодируется следующим образом:
Позиции 0xf5a1-0xfefe (всего 940 символов) в CS1 - это основная область, зарезервированная для пользовательских символов.
Позиции 0x8ff5a1-0x8ffefe (всего 940 символов) в CS3 - это вспомогательная область, зарезервированная для пользовательских символов.
EUC для упрощенного китайского языка - это кодовый набор, состоящий из однобайтовых и двухбайтовых символов. Данная кодировка EUC основана на стандарте ISO2022, стандарте GB2312 для КНР и определениях многобайтовых символов, уникальных для производителя.
Современная кодировка GB2312 включает в себя 6763 символа упрощенного китайского языка и 682 дополнительных знака. IBM-eucCN представляет собой одну таблицу, которая может кодировать до 94x94 символов. Кодовые значения лежат в интервале 0xa1a1-0xfefe.
GB2312 отображается на первый кодовый набор (CS1) EUC. Кодовый набор
IBM-eucCN состоит из следующих наборов символов:
| ISO0646-IRV | Набор 7-разрядных ASCII символов, относится к левой группе. |
| GB2312.1980 | Содержит 7445 символов. Занимает часть позиций в интервале 0xa1a1-0xfedf. |
| IBM-udcCN | Символы расположены группами в области GB в интервале
Oxa1a1-Oxfedf. Ниже перечислены эти группы:
a2a1 -- a2b0 a1e3 -- a2e4 a1ef -- a2f0 a2fd -- a1fe a4f4 -- a4fe a5f7 -- a5fe a6b9 -- a6c0 a6d9 -- a6fe a7c2 -- a7d0 a7f2 -- a7fe a8bb -- a8c4 a8ea -- a9a3 a9f0 -- affe a7fa -- d7fe f8a1 -- fedf |
| IBM-sbdCN | Символы расположены группами в области GB в интервале 0xfee0-0xfefe. |
Сокращение GBK означает следующее: Guo Biao Kuo (Расширение
национального стандарта). Это расширение дополняет национальный
"Промышленный стандарт GB"; дополненный стандарт включает 20902
определенных в Unicode символа Хан и дополнительные символы DBCS, определенные
в коде Big-5 (стандарт де-факто традиционного китайского языка для PC).
Такой стандарт GBK содержит все символы DBCS, применяемые в КНР и на
Тайване. В настоящее время GBK признан нормативным дополнением
стандарта GB13000 (PRC стандарт Unicode) и рассматривается как промежуточное
звено для перехода к Unicode.
| Локаль | Кодовый набор | Описание |
|---|---|---|
| Zh_CN | GBK | Упрощенный китайский, локаль GBK |
| Интервал кодов | Число слов | Примечания |
|---|---|---|
| A1A1-A9FE | 846 | GB2312, GB12345 (GBK/1) |
| A840-A9A0 | 192 | Big5, Символы (GBK/5) |
| B0A1-F7FE | 6768 | GB2312 (GBK/2) |
| 8140-A0FE | 6080 | GB13000 (GBK/3) |
| AA40-FEA0 | 8160 | GB13000 (GBK/4) |
| AAA1-AFFE | 564 | Пользовательские (группа 1) |
| F8A1-FEFE | 658 | Пользовательские (группа 2) |
| A140-A7A0 | 672 | Пользовательские (группа 3) |
EUC для традиционного китайского языка - это кодовый набор, состоящий из одно-, двух- и четырехбайтовых символов. Данная кодировка EUC основана на стандарте ISO2022, стандарте CNS, определенном в Китае, и определениях многобайтовых символов, уникальных для производителя.
В настоящее время стандарт CNS кодирует 13501 символ китайского языка и 684 дополнительных знака. IBM-eucTW содержит 15 кодовых таблиц по 8836 (94x94) символов каждая. Кодовые значения лежат в интервале 0xa1a1-0xfefe. В настоящее время только 4 таблицы кодируют символы, а оставшиеся зарезервированы для использования в будущем.
15 таблиц отображены на кодовые наборы EUC CS1 и CS2, при этом на долю CS2
приходится 14 из них. Кодовый набор IBM-eucTW состоит из следующих
наборов символов:
| ISO646-IRV | Набор 7-разрядных ASCII символов, относится к левой группе. |
| CNS11643.1986-1 | Таблица 1, содержит 6085 символов (5401+684). Занимает позиции 0ax1a1-0xc2c1 и 0xc4a1-0xfdcb. |
| CNS11643.1986-2 | Таблица 2, содержит 7650 символов. Занимает позиции 0x8ea2a1a1-0x8ea2f2c4. |
| CNS11643.1992-3 | Таблица 4, содержит 7298 символов. Занимает позиции 0x8ea4a1a1-0x8ea4eedc. |
| IBM-udcTW | Таблица 12, содержит 6204 символов. Эта область зарезервирована для пользовательских символов (udc). Занимает позиции 0x8eaca1a1-0x8ea2f2c4. |
| IBM-sbdTW | Таблица 13, содержит 325 символов. Эта область зарезервирована для символов, уникальных для производителя. Занимает позиции 0xeada1a1-0x8eada4cb. |
Таблицы 3-11 предположительно будут занимать позиции 0x8ea3xxxx-0x8eabxxxx; таблицы 14-15 - позиции 0x8eaexxxx-0x8eafxxxx.
Кодовый набор Zh_TW локали big5 является наиболее распространенным кодовым набором традиционного китайского языка для PC.
Набор Big5 содержит 13056 символов китайского языка и 1004 дополнительных
знака. Он включает 684 символов CNS11643.192 и 325 уникальных
символов фирмы IBM.
| Локаль | Кодовый набор | Описание |
|---|---|---|
| Zh_TW | Big5 (IBM-950) | Традиционный китайский, локаль Big5 |
| Таблица | Интервал кодов | Описание |
|---|---|---|
| 1 | A140H - A3E0H | Коды дополнительных знаков и управляющих китайских символов |
| 1 | A440H - C67EH | Общеупотребительные символы |
| 2 | C940H - F9D5H | Более редкие символы |
| UDF | FA40H - FEFE | Пользовательские символы |
|
| 8E40H - A0FEH | Пользовательские символы |
|
| 8140H - 8DFEH | Пользовательские символы |
|
| 8181H - 8C82H | Пользовательские символы |
|
| F9D6H - F9F1H | Пользовательские символы |
| Кодовый набор | Число слов | Интервал кодов | Примечания |
|---|---|---|---|
| Область общеупотре- бительных символов | 5841 | A140-C67E |
|
| Область редких символов | 7652 | C940-F9D5 |
|
| Область уникальных символов ET (1) | 308 | C6A1-C878 |
|
| Область уникальных символов ET (2) | 7 | C8CD-C8D3 |
|
| Область уникальных символов фирмы IBM | 251 | F286-F9A0 | Кодовые значения 81-A0 в области младших байт |
| Область пользовательских символов (1) | 785 | FA40-FEFE |
|
| Область пользовательских символов (2) | 2983 | 8E40-A0FE |
|
| Область пользовательских символов (3) | 2041 | 8140-8DFE |
|
| Область пользовательских символов (4) | 354 | 8181-8C82 | Кодовые значения 81-A0 в области младших байт |
| Область пользовательских символов (5) | 41 | F9D6-F9FE |
|
EUC для корейского языка - это кодовый набор, состоящий из однобайтовых и многобайтовых символов. Он основан на стандарте ISO2022, Корейском стандартном кодовом наборе и определениях EUC.
Набор корейских символов EUC состоит из двух основных групп:
Кодовый набор Хангул включает не только корейские (Хангул), но и китайские (Ханжа) символы. Один символ Хангул может состоять из нескольких гласных и согласных. Вместе с тем, большинство слов языка Хангул можно записать символами Ханжа. Каждый символ Ханжа имеет собственное значение, более определенное, чем символы Хангул.
Кодовый набор IBM-eucKR состоит из следующих наборов символов:
| ISO646-IRV | Набор 7-разрядных символов ASCII, относится к левой группе. |
| KSC5601.1987-0 | Набор корейских графических символов, относится к правой группе. |
Кодовые наборы IBM PC - это кодовые наборы, которые изначально поддерживались операционными системами IBM PC и AIX. В кодовых наборах IBM PC первая управляющая область (C1) отведена под графические символы. Те приложения, которые зависят от управляющих символов из области C1, не поддерживают эти кодовые наборы.
Коды ASCII-символов имеют нули в самом старшем разряде (MSB) и
располагаются в позициях 0x20-0x7e. Расширенный набор Латиница-1 и
уникальные символы IBM PC образуют расширенный набор, который кодируется в
позициях 0x80-0xfe. В следующей таблице показано расположение символов
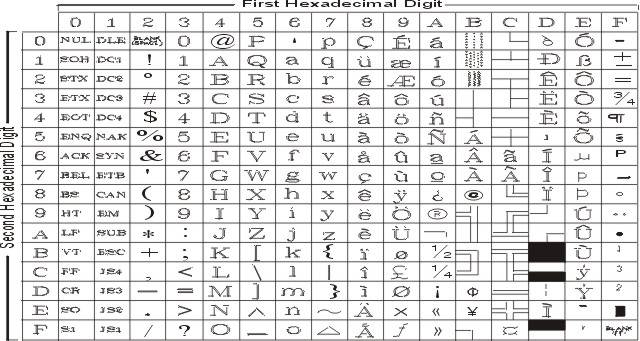
ASCII, управляющих и расширенных символов в кодовом наборе IBM-850.
| Кодировка | Кодовые знаки | Описание | Количество |
| 000xxxxx | 00-1F | Управляющие символы | 32 |
| 00100000 | 20 | Пробел | 1 |
| 0xxxxxxx | 21-7E | 7-разрядные символы | 94 |
| 01111111 | 7F | Delete | 1 |
| 1xxxxxxx | 80-FE | 8-разрядные символы | 17 |
| 11111111 | FF | Все единицы | 1 |
Набор уникальных символов IBM PC состоит из следующих компонентов:
| Набор уникальных символов IBM PC | |
| Символ | Код возврата |
| Знак флорина | 0x9f |
| Редкая сетка | 0xb0 |
| Средняя сетка | 0xb1 |
| Частая сетка | 0xb2 |
| Вертикальная черта | 0xb3 |
| Вертикальная черта с левой поперечиной | 0xb4 |
| Вертикальная черта с левой поперечиной (двойная линия) | 0xb9 |
| Вертикальная черта (двойная линия) | 0xba |
| Угол в левой нижней четверти (двойная линия) | 0xbb |
| Угол в левой верхней четверти (двойная линия) | 0xbc |
| Угол в левой нижней четверти | 0xbf |
| Угол в правой верхней четверти | 0xc0 |
| Горизонтальная черта с верхней поперечиной | 0xc1 |
| Горизонтальная черта с нижней поперечиной | 0xc2 |
| Вертикальная черта с правой поперечиной | 0xc3 |
| Горизонтальная черта | 0xc4 |
| Крест | 0xc5 |
| Угол в правой верхней четверти (двойная линия) | 0xc8 |
| Угол в правой нижней четверти (двойная линия) | 0xc9 |
| Горизонтальная черта с верхней поперечиной (двойная линия) | 0xca |
| Горизонтальная черта с нижней поперечиной (двойная линия) | 0xcb |
| Вертикальная черта с правой поперечиной (двойная линия) | 0xcc |
| Горизонтальная черта (двойная линия) | 0xcd |
| Крест (двойная линия) | 0xce |
| Уменьшенная римская цифра I | 0xd5 |
| Угол в левой верхней четверти | 0xd9 |
| Угол в правой нижней четверти | 0xda |
| Закрашенная ячейка | 0xdb |
| Закрашенная наполовину снизу ячейка | 0xdc |
| Закрашенная наполовину сверху ячейка | 0xdf |
| Черточка сверху | 0xee |
| Точка в центре | 0xfa |
| Закрашенный прямоугольник | 0xfe |
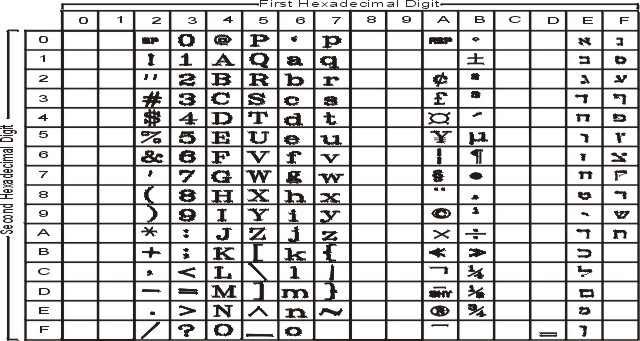
На рисунке показаны все символы и раскладка кодового набора IBM-850. Текстовое представление этого кодового набора приведено в разделе IBM-850.
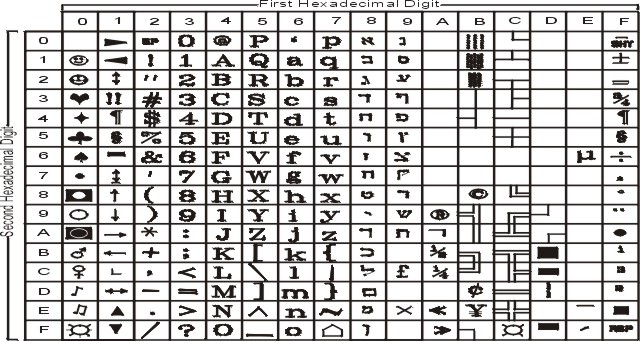
На рисунке показаны все символы и раскладка кодового набора IBM-856. Текстовое представление этого кодового набора приведено в разделе IBM-856.
На рисунке показаны все символы и раскладка кодового набора IBM-921. Текстовое представление этого кодового набора приведено в разделе IBM-921.
На рисунке показаны все символы и раскладка кодового набора IBM-922. Текстовое представление этого кодового набора приведено в разделе IBM-922.
Каждый из кодовых наборов IBM PC для японского языка состоит из однобайтовых и многобайтовых символов. Все наборы основаны на кодовом наборе IBM PC; символам JIS соответствуют комбинации вида Shift+клавиша. Такая кодировка называется Shift-JIS или SJIS.
IBM-943 - это усовершенствованный по сравнению с IBM-932 кодовый набор для японской локали. Он совместим с японской версией Microsoft Windows. Его также называют упорядоченным shift-JIS 1983. Ниже приведены различия между наборами IBM-932 и IBM-943:
Кодовый набор IBM-932 состоит из следующих наборов символов:
| JISCII | Левая группа символов JISX0201 |
| JISX0201.1976 | Правая группа символов Катакана/Хирагана |
| JISX0208.1983 | Наборы символов Канжи уровней 1 и 2 |
| IBM-udcJP | Пользовательские символы |
Кодовый набор IBM-943 состоит из следующих наборов символов:
| JISCII | Левая группа символов JISX0201 |
| JISX0201.1976 | Правая группа символов Катакана/Хирагана |
| JISX0208.1990 | Наборы символов Канжи уровней 1 и 2 |
| IBM-udcJP | Пользовательские символы, избранные символы NEC и некоторые символы NEC, применяемые фирмой IBM |
Первый байт каждого символа определяет его число байтов. Значения
0x20-0x7e и 0xa1-oxdf кодируют символы JISX0201, за некоторыми
исключениями. Позиции 0x81-0x9f и 0xe0-0xfc зарезервированы, они будут
определять первые байты многобайтовых символов. Символам JISX0208
присвоены многобайтовые значения начиная с 0x8140. Второй байт
многобайтового символа может быть любым. Таблица Shift-JIS иллюстрирует
расположение этих символов в кодовом наборе.
Табл. 16-4. Схема кодировок Shift-JIS (IBM-943 и IBM-932) для японского языка
| Кодировка | Кодовый знак | Описание | Количество |
| 000xxxxx | 00-1f | Управляющие символы | 32 |
| 00100000 | 20 | Пробел | 1 |
| 0xxxxxxx | 21-7E | 7-разрядные символы ASCII | 94 |
| 01111111 | 7F | Delete | 1 |
| 10000000 | 80 | Не определен | 1 |
| 100xxxxx 01xxxxxx | [81-9F] [40-7E] | Двухбайтовые символы | 1953 |
| 100xxxxx 1xxxxxxx | [81-9F] [80-FC] | Двухбайтовые символы | 3975 |
| 10100000 | A0 | Не определен | 1 |
| 1xxxxxxx | A1-DF | 8-разрядные однобайтовые символы | 63 |
| 111xxxxx 01xxxxxx | [E0-FC] [40-7E] | Двухбайтовые символы | 1827 |
| 111xxxxx 1xxxxxxx | [E0-FC] [80-FC] | Двухбайтовые символы | 3625 |
| 11111101 | FD | Не определен | 1 |
| 11111110 | FE | Не определен | 1 |
| 11111111 | FF | Не определен | 1 |
В следующей таблице показаны символы DBCS, которые входят в набор
IBM-943.
Табл. 16-5. Двухбайтовые символы набора IBM-943
| Кодовый знак | Описание |
| [81-84] [40-7E] и [81-84] [80-F0] | JIS X 0208 (не Канжи) |
| [87] [40-7E] и [87] [80-F0] | Отдельные символы NEC |
| [89-98] [40-7E] и [88] [9F-F0], [89-97] [80-F0], [98] [80-9F] | JIS X0208 (Канжи, уровень 1) |
| [99-9F] [40-7E] и [98] [9F-F0], [99-9F] [80-F0] | JIS X0208 (Канжи, уровень 2) |
| [E0-EA] [40-7E] и [E0-EA] [80-F0] | JIS X0208 (Канжи, уровень 2) |
| [ED-EE] [40-7E] и [ED-EE] [80-F0] | Отдельные символы NEC, выбранные IBM |
| [F0-F9] [40-7E] и [F0-F9] [80-F0] | Пользовательские символы |
| [FA] [40-5C] | Отдельные символы, выбранные IBM (не Канжи) |
| [FA] [5C-7E], [FB-FC] [40-7E] и [FA-FC] [80-F0] | Отдельные символы, выбранные IBM (Канжи) |
В следующей таблице показаны символы DBCS, которые входят в набор
IBM-932.
| Кодовый знак | Описание |
| [81-98] [40-7E] и [81-97] [80-FC], [98] [80-9F] | JIS X 0208 (Канжи, уровень 1) |
| [99-9F] [40-7E] и [98] [9F-FC], [99-9F] [80-FC] | JIS X 0208 (Канжи, уровень 2) |
| [E0-EF] [40-7E] и [E0-EF] [80-FC] | JIS X 0208 (Канжи, уровень 2) |
| [F0-F9] [40-7E] и [F0-F9] [80-FC] | Пользовательские символы |
| [FA-FC] [40-7E] и [FA-FC] [80-FC] | Отдельные символы, выбранные IBM |
На рисунке показаны все символы и раскладка кодового набора IBM-1046. Текстовое представление этого кодового набора приведено в разделе IBM-1046.
На рисунке показаны все символы и раскладка кодового набора IBM-1124. Текстовое представление этого кодового набора приведено в разделе IBM-1124.
На рисунке показаны все символы и раскладка кодового набора IBM-1129. Текстовое представление этого кодового набора приведено в разделе IBM-1129.
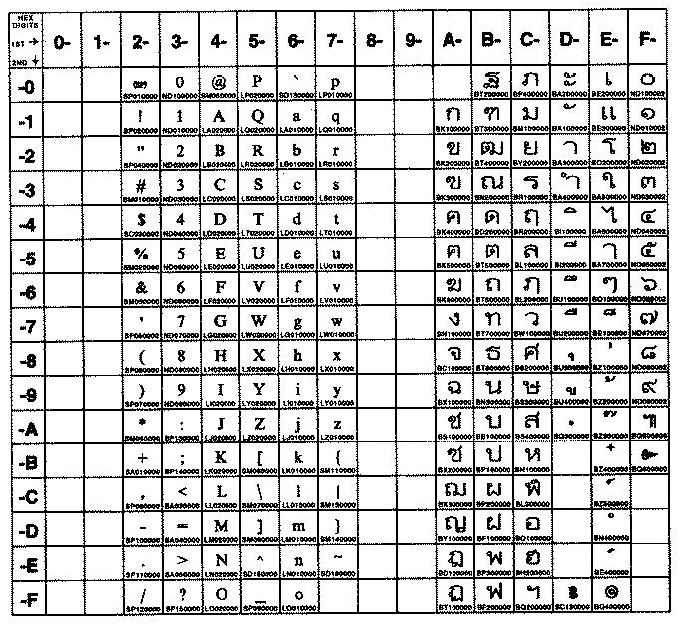
На рисунке показаны все символы и раскладка кодового набора TIS-620. Текстовое представление этого кодового набора приведено в разделе TIS-620.
AIX предоставляет кодовые наборы для различных языков (или групп языков). При этом ни один из наборов, принадлежащих к семейству ISO8859, кодовым наборам PC или кодовым наборам EUC (Расширенный код Unix), не позволяет смешивать символы разных кодировок. ISO8859-1 позволяет использовать любые символы из набора Латиница-1 (которую применяют в США, Канаде, странах Западной Европы и Латинской Америки). ISO8859-2 включает наборы символов для стран Восточной Европы; ISO8859-5 - кириллицу, ISO8859-6 - арабские символы, ISO8859-7 - греческие, ISO8859-8 - символы иврит, ISO8859-9 - турецкие, IBM-eucJP - японские, IBM-eucKR - корейские, IBM-eucTW - символы упрощенного китайского языка. Проблема заключается в том, что ни один из этих наборов не поддерживает все языки одновременно.
По этой причине, Международная организация по стандартизации (ISO) приняла Unicode в качестве кодировки для двухбайтовых символов (2-октетная форма), относящихся к Универсальному набору многобайтовых символов ISO10646 (UCS-2). 32-разрядную разновидность ISO10646 называют UCS-4 (так как она является 4-октетной формой). В AIX принята 16-разрядная разновидность ISO10646 с ее стандартным обозначением UCS-2.
Хотя UCS-2 идеально подходит в качестве кодировки для внутренних процессов, она не годится для кодирования текстовой информации в стандартных байт-ориентированных системах, таких как AIX. Поэтому в качестве кодировки для внешних файлов применяется формат "X/Open's File System Safe UCS Transformation Format" (FSS-UTF). Эта кодировка также называется UTF-8, именно так она и обозначается в AIX.
Универсальный набор кодированных символов (UCS) - это название стандарта ISO10646, определяющего единый код для представления, пересылки, обработки, хранения, ввода и печати информации на всех основных языках мира.
Введение стандарта UCS преследует следующие цели:
Стандарт ISO10646 определяет канонические символьные коды длиной 32 разряда. Такая длина позволяет закодировать более 4 миллиардов символов. Если кодировка применяется в канонической форме для представления текста, то ее называют UCS-4 (4-байтовая форма Универсального набора кодированных символов).
Кодовые значения из диапазона 0x0000-0xFFFF стандарта ISO10646 можно представить с помощью 16-разрядного кодирования. В этом случае кодировку называют UCS-2 (2-октетная форма). Этот диапазон также называют Базовой многоязычной таблицей (BMP) стандарта ISO10646. Стандарт ISO10646 организован таким образом, что все наиболее общеупотребительные символы основных языков мира кодируются значениями из этого диапазона.
Кодовые значения символов UCS-2 совпадают с кодировками стандарта Unicode, опубликованными консорциумом Unicode.
UCS-2 определяет коды письменных знаков основных языков мира. Кроме наборов научных, математических и издательских символов, UCS-2 включает в себя символы следующих языков и алфавитов:
Возможность представления перечисленных символов в AIX ограничена только наличием соответствующих шрифтов. В AIX имеются растровые шрифты для большинства основных языков мира, а также масштабируемый шрифт TrueType на основе стандарта Unicode. Для того чтобы работать с этим шрифтом, необходим растеризатор шрифта TrueType для AIX, устанавливаемый отдельно.
В UCS-2 предусмотрено несколько специальных знаков, называемых знаками
комбинирования или знаками "без пробела" и предназначенных для ввода символов
с диакритическими знаками. Такие символы встречаются в некоторых
шрифтах, например хинди, тайском, арабском и иврите. Знаки
комбинирования применяют и для ввода некоторых символов латинского и
греческого шрифтов и кириллицы. Однако наличие знаков комбинирования
допускает возможность альтернативного кодирования текста. Хотя эти
кодирования позволяют однозначно восстановить исходный текст и сохраняют
целостность данных, обработка текста со знаками комбинирования
усложняется. С целью обеспечить совместимость с приложениями, не
применяющими знаков комбинирования, стандарт ISO10646 определяет следующие три
уровня реализации:
| Уровень 1 | Знаки комбинирования запрещены. |
| Уровень 2 | Разрешены знаки комбинирования следующих шрифтов: тайского, арабского, хинди и иврит. |
| Уровень 3 | Разрешены любые знаки комбинирования (в т.ч. для латиницы, кириллицы и греческого алфавита). |
Фирмой X/Open разработан формат преобразования для UCS, предназначенный для существующих файловых систем. Первоначально этот формат назывался FSS-UTF, но, скорее всего, будет зарегистрирован ISO под именем UTF-8. Формат UTF-8 предположительно станет стандартным для тех случаев, когда применение UCS нецелесообразно. UCS будет выполнять роль кода процесса для формата преобразования, который, в свою очередь, можно будет использовать в качестве файлового кода.
Ниже перечислены свойства UTF-8:
Значения UCS из диапазона 0-0x7FFFFFFF кодируются в UTF-8 с помощью
многобайтовых символов (длиной 1, 2, 3, 4, 5 и 6 байт). Однобайтовые
значения в диапазоне 0-0x7f зарезервированы для символов ASCII. Их
старший бит равен 0. Во всех кодах символов, состоящих более чем из
одного байта, первый байт определяет общее число байт, а старший разряд
каждого байта имеет фиксированное значение. Если байт не начинается с
битовой комбинации 10xxxxxx, где x - 0 или 1, то он является началом
кодирующей последовательности символа UCS.
| Коды многобайтовых символов UTF-8 | ||||
| Байты | Биты | Мин. шестн. значение | Макс. шестн. значение | Поразрядное представление |
| 1 | 7 | 00000000 | 0000007F | 0xxxxxxx |
| 2 | 11 | 00000080 | 000007FF | 110xxxxx 10xxxxxx |
| 3 | 16 | 00000800 | 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 00010000 | 001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 5 | 26 | 00200000 | 03FFFFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxx 10xxxxxx |
| 6 | 31 | 04000000 | 7FFFFFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
Значение UCS - это просто совокупность битов x многобайтового кодового значения. Если возможны различные способы кодирования значения (например, UCS 0), то допускается только кратчайший вариант.
UCS-2 кодируется следующим подмножеством UTF-8:
| Коды многобайтовых символов UTF-8 | ||||
| Байты | Биты | Мин. шестн. значение | Макс. шестн. значение | Поразрядное представление |
| 1 | 7 | 00000000 | 0000007F | 0xxxxxxx |
| 2 | 11 | 00000080 | 000007FF | 110xxxxx 10xxxxxx |
| 3 | 16 | 00000800 | 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
Все значения этого подмножества UTF-8 должны состоять не более чем из 3 байт.
Раздел Low Function Terminal (LFT) Subsystem Overview руководства AIX 5L Version 5.1 Kernel Extensions and Device Support Programming Concepts.
Разделы Поддержка национальных языков при управлении системой, Поддержка национальных языков при работе с устройствами и Локали при управлении системой руководства Руководство по управлению системой AIX 5L версии 5.1: Операционная система и устройства.
Команда iconv.